![FAIRtracks-logo-light-white-320-[fixed].png](/_nuxt/img/6639f7d.png)
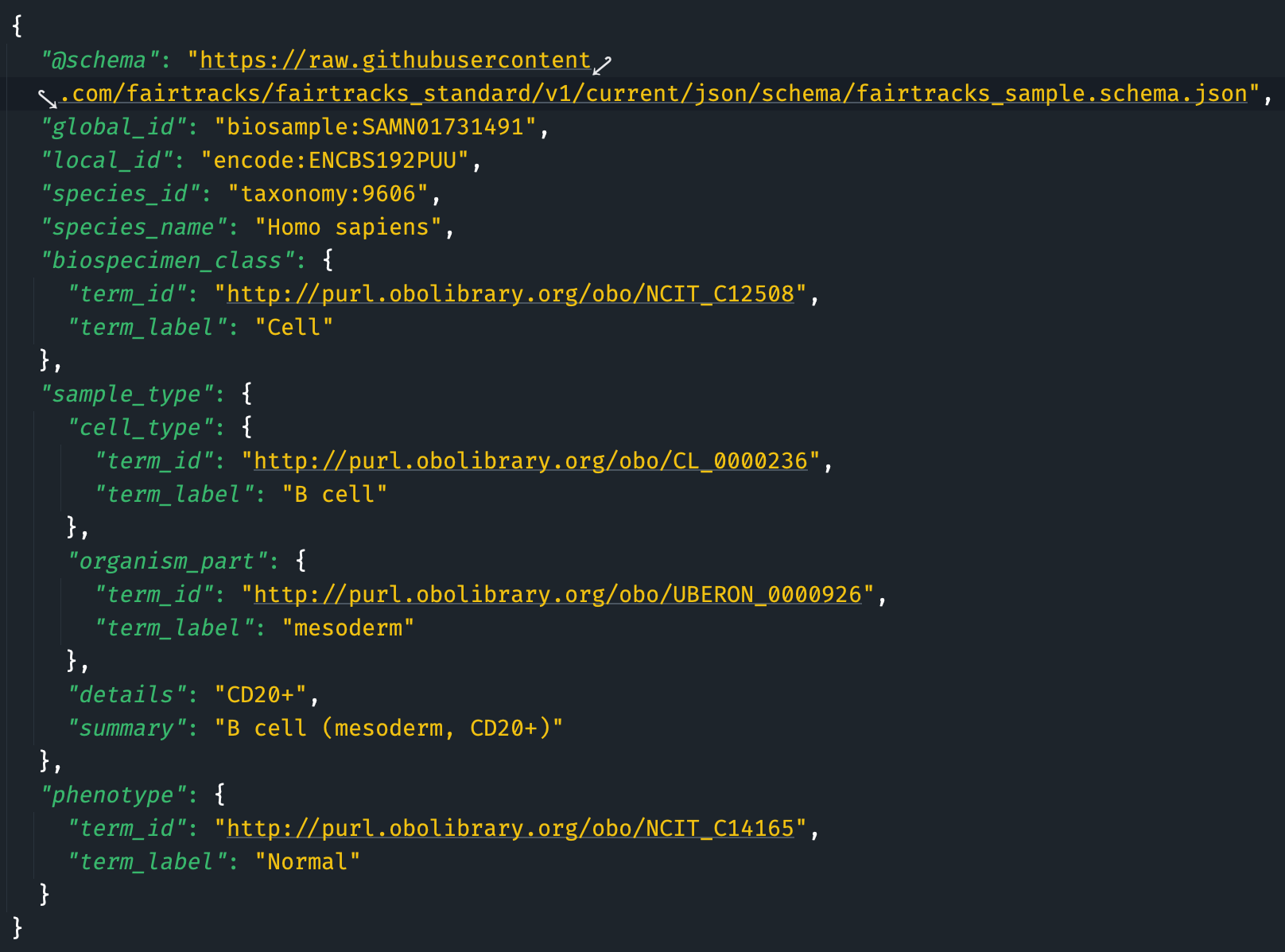
Figure 1.1: Example FAIRtracks JSON object, adhering to the Sample subschema
FAIRtracks metadata standard
Generic and FAIR exchange standard for track metadata
FAIRtracks is a draft standard for genomic track metadata that adheres closely to the FAIR principles (that research data should be Findable, Accessible, Interoperable, and Reusable). FAIRtracks is implemented as a set of JSON Schemas organized around a set of main object types:
track collections - studies - experiments - samples - track files
Metadata fields. For each of these object, we have selected a set of minimal fields that we have found helpful for data analysis. All of these objects can refer directly to records in other repositories containing richer metadata. With this solution, we can enforce the strictness in the core metadata fields required to provide accurate categorical search functionality to end-users. At the same time, data providers can add custom fields directly in the FAIRtracks document or in external records, so that the standard still allows for "extensive and generous metadata" as recommended by FAIR principle F2.
Connecting the dots. As a result, FAIRtracks can bridge specialized data portals and analysis tools. As a proof of concept, we have implemented a set of services that comprise the FAIRtracks ecosystem, including metadata validation and search capabilities through the TrackFind service. FAIRtracks makes heavy use of ontologies, while the identifiers are actionable through the services Identifiers.org and N2T.net.
Figure 1.1: Example FAIRtracks JSON object, adhering to the Sample subschema
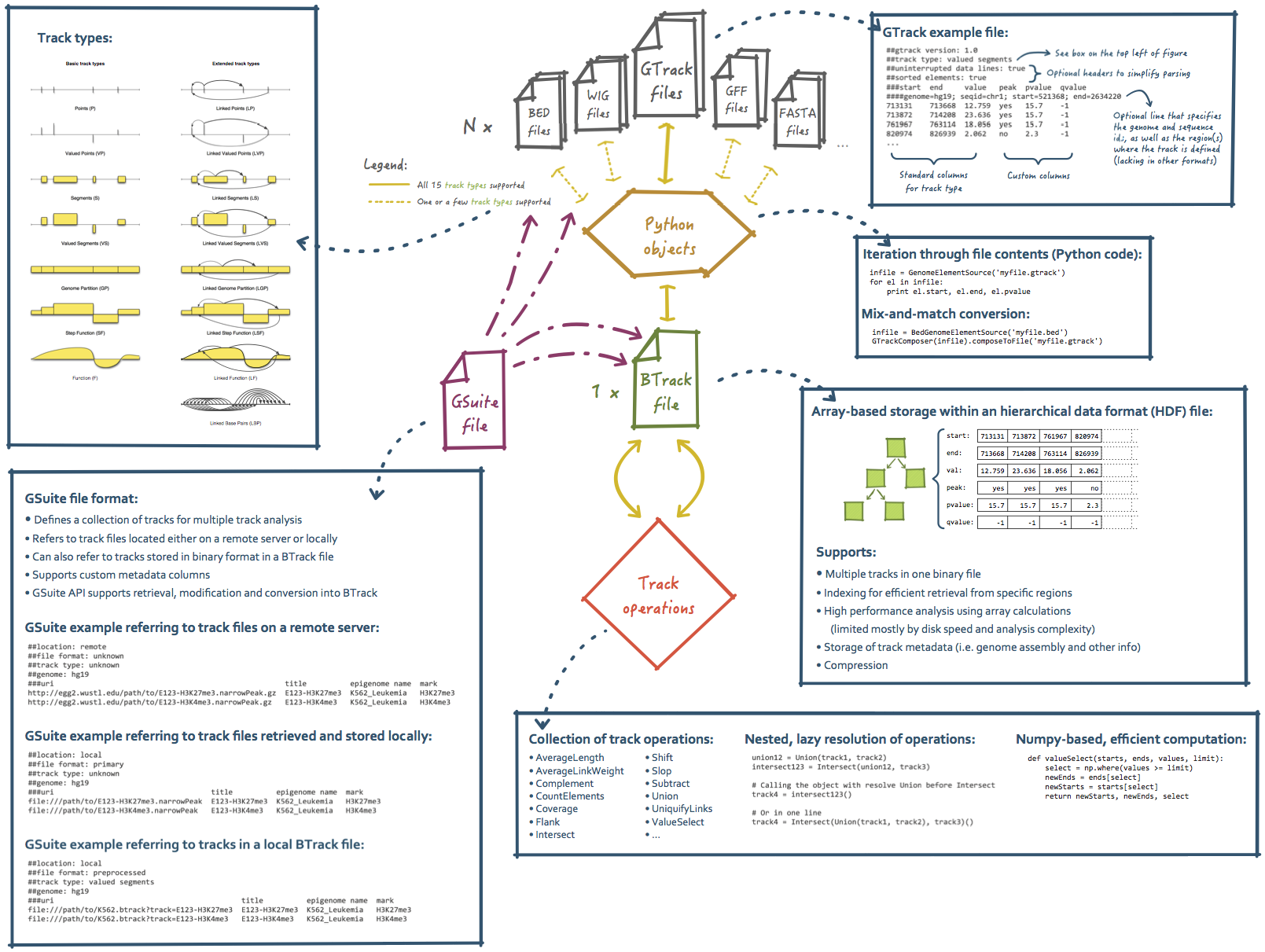
Figure 2.1: Overview of the different components of the GTrack ecosystem, which consists of the GTrack, Btrack, and GSuite file formats.
The GTrack ecosystem
Expressive file formats for analysis of genomic track data
The GTrack ecosystem is a set of file formats designed to handle genomic track data of heterogeneous types. The file formats are designed to complement each other and work jointly as a complete ecosystem for representation and analysis of most types of data that can be located along a reference genome. Figure 2.1 illustrates the file formats in the GTrack ecosystem, and their interdependencies.
The GTrack ecosystem consists of:
- GTrack: uniform tabular file format for track data
- BTrack: binary version of GTrack
- GSuite: tabular file format for track metadata
The file formats will be presented in more detail in the following sections. `
Figure 2.1: Overview of the different components of the GTrack ecosystem, which consists of the GTrack, Btrack, and GSuite file formats.

Figure 3.1: Example GTrack file [detail from Figure 2.1, above]
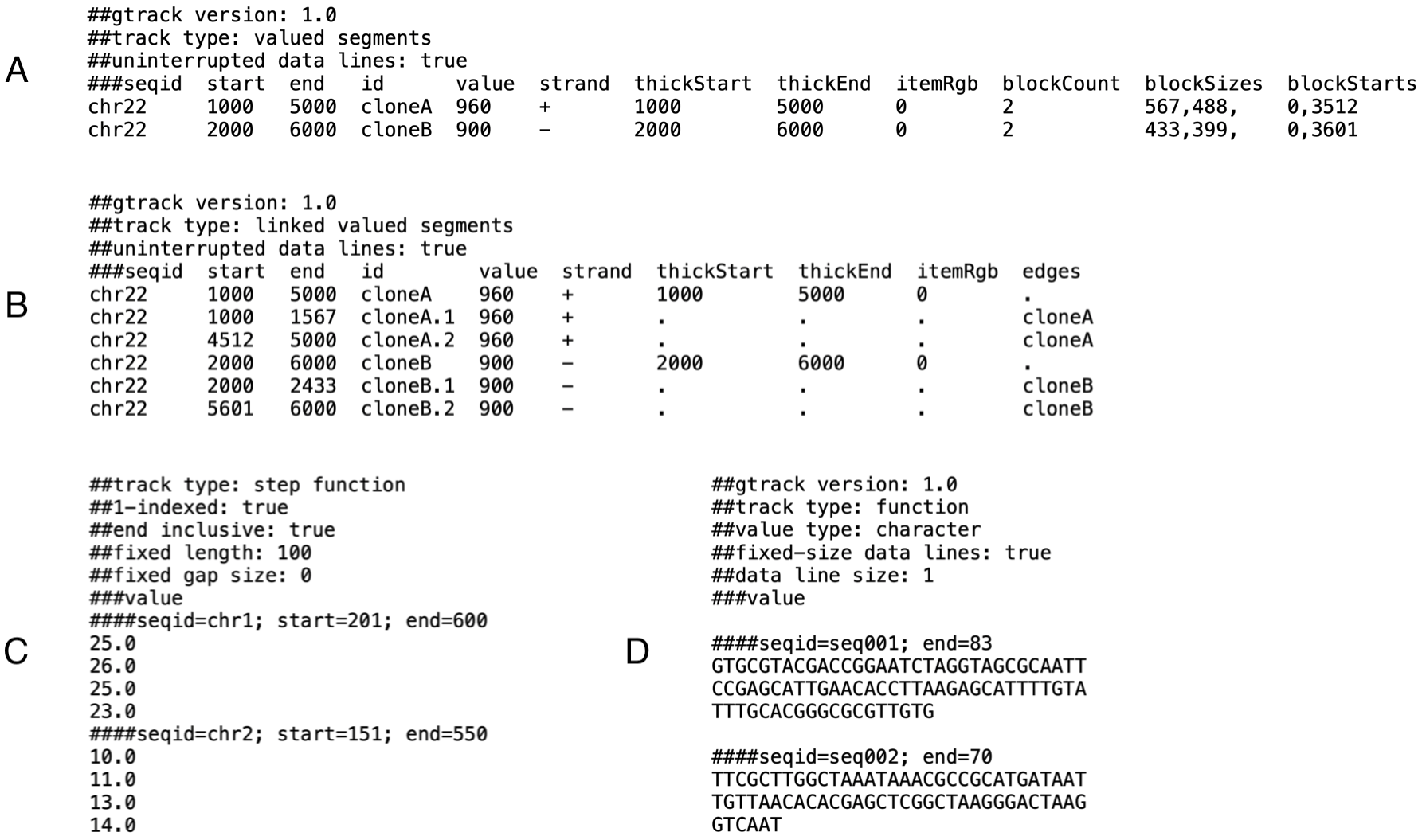
Figure 3.2: GTrack variants of common file formats. (A) BED - directly column-mapped variant. (B) BED - refactored as a GTrack file with exon segments linked to parent transcript segments. (C) WIG as GTrack file of track type "Step Function". (D) FASTA as GTrack file of track type "Function".
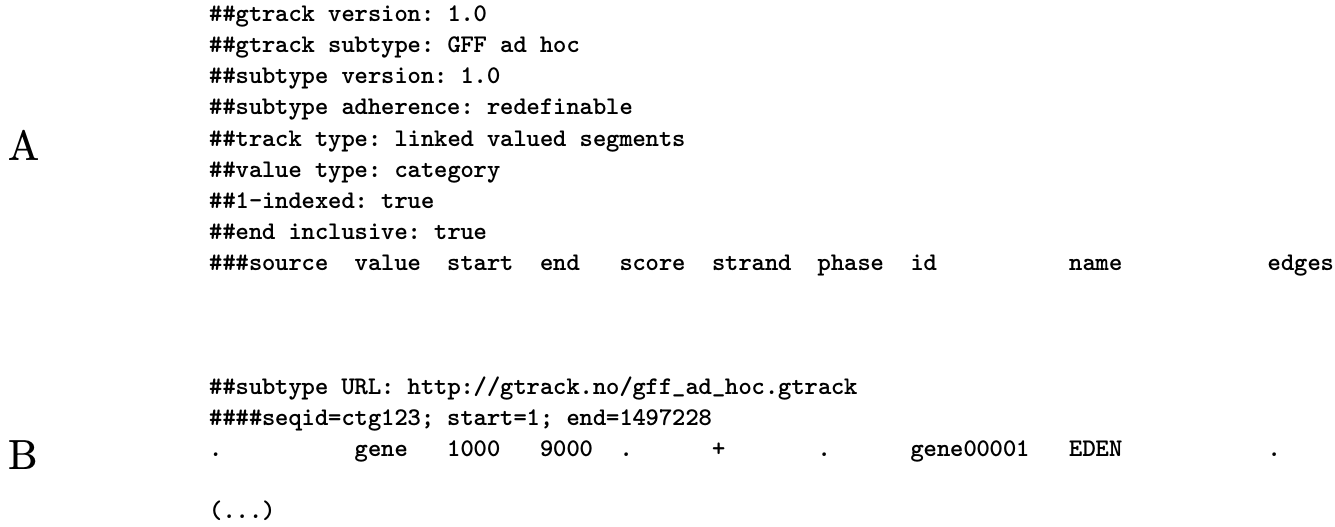
Figure 3.3: Example of GTrack subtype [from Gundersen, S et al., 2011]. (A) A GTrack subtype specification file is defined from a set of header variables and/or a column specification line, and made available from a URL. (B) Other GTrack files adhering to the subtype only need to prepend the URL to the subtype file in the "subtype URL" header. The parser will then download the subtype specification and validate the file accordingly. A set of basic GTrack subtypes are available for use with the following URL pattern: http://gtrack.no/[subtype].gtrack
GTrack and BTrack file formats
Uniform file formats for heterogeneous track data
GTrack is a tabular format that was developed to provide a uniform representation of most types of genomic datasets. It was developed in parallel to the concept of Track types as a track data file format capable of representing all 15 track types. Commonly used file formats are limited to represent only a subset of the various track types. Thus, GTrack is able to replace most common file formats, such as WIG, GFF, BED, and FASTA (Figure 3.2), as well as represent 3D-type datasets produced by chromatin capture technologies such as Hi-C and ChIA-PET.
GTrack is able to replace most common file formats
In addition to this versatility, GTrack also introduced several conceptual advantages to most existing file format that aims to future-proof GTrack parsers:
Custom headers. The reserved GTrack headers are used to describe the particular configuration of a GTrack file, and can as such be used by analysis tools to easily validate whether the input data files are formatted as required. In addition, GTrack allows for the addition of any number of custom headers, in any order.
Custom data columns. GTrack allows the addition of any number of custom columns, in any order, as defined by a column specification line.
Bounding regions. As one of few file formats, GTrack allows the specification of the regions of the reference genome where the track is defined. This is important for analysis, as there is a big difference between the lack of a track element (e.g. a segment) due to the lack of a feature or only due to missing data (e.g. in centromere regions).
GTrack subtypes. As illustrated in Figure 3.3, a particular configuration of header variables and/or columns can be assigned as a GTrack subtype and used for validation of other GTrack files. This allows for parsers to be fixed towards particular sub-variants of GTrack if stricter validation is needed for particular use cases. Hence, for many of the most common file formats, the prepending of a single header variable line is the only thing that is needed to turn it into a GTrack file.
The BTrack format supports the same variety of informational content as GTrack, but in binary form. A first version of BTrack is implemented as NumPy-based arrays mapped to files. A second, single-file version of BTrack as an exchange format is currently only implemented as a prototype.
GTrack and BTrack are supported by the the Genomic HyperBrowser, as well as the GTrackCore Python library.
Figure 3.1: Example GTrack file [detail from Figure 2.1, above]
Figure 3.2: GTrack variants of common file formats. (A) BED - directly column-mapped variant. (B) BED - refactored as a GTrack file with exon segments linked to parent transcript segments. (C) WIG as GTrack file of track type "Step Function". (D) FASTA as GTrack file of track type "Function".
Figure 3.3: Example of GTrack subtype [from Gundersen, S et al., 2011]. (A) A GTrack subtype specification file is defined from a set of header variables and/or a column specification line, and made available from a URL. (B) Other GTrack files adhering to the subtype only need to prepend the URL to the subtype file in the "subtype URL" header. The parser will then download the subtype specification and validate the file accordingly. A set of basic GTrack subtypes are available for use with the following URL pattern: http://gtrack.no/[subtype].gtrack

Figure 4.1: A few GSuite example files, illustrating core properties of the file format [detail from Figure 2.1, above]
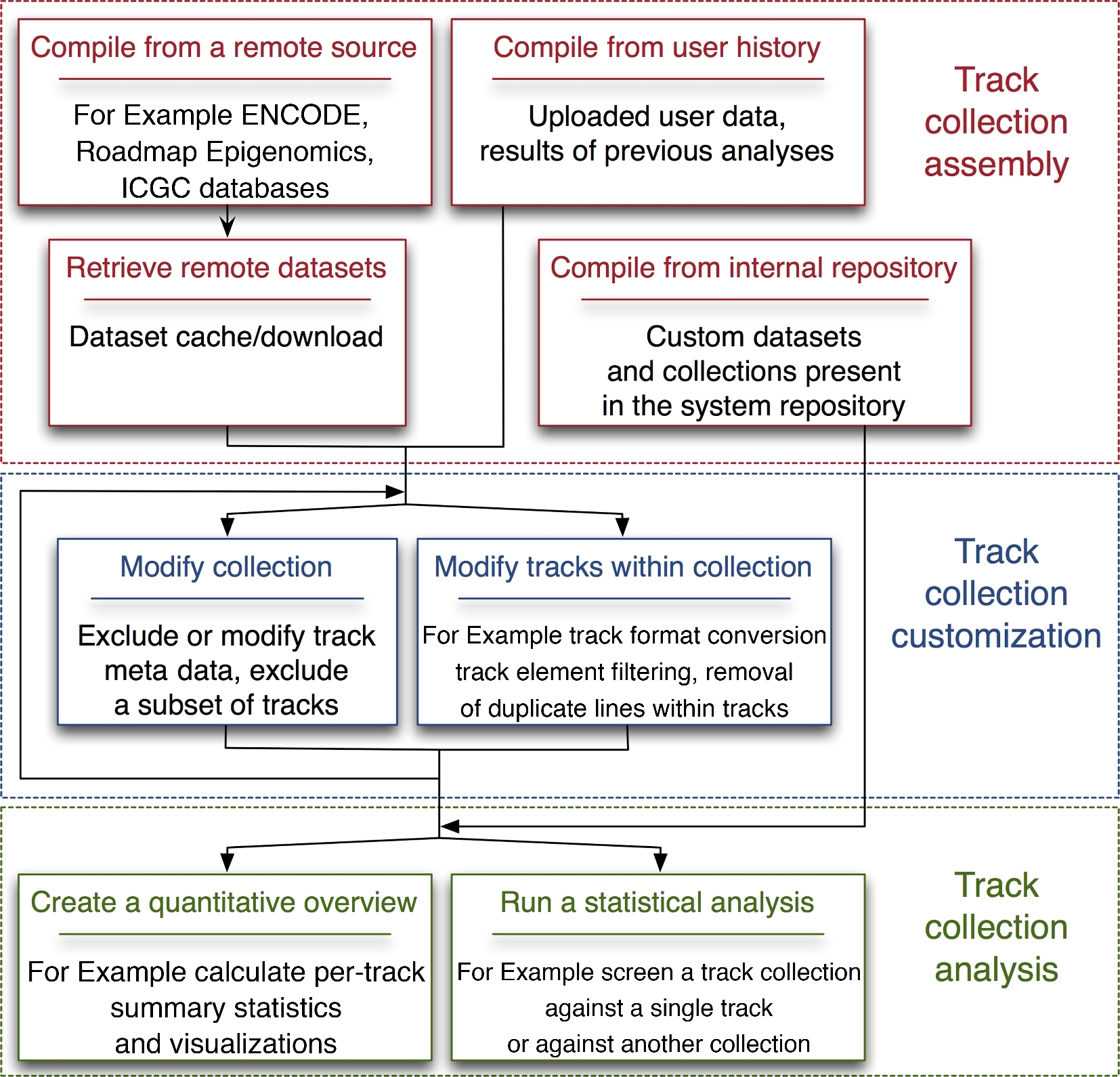
Figure 4.2: Multi-track analysis flow built around the GSuite file format, as implemented in the GSuite HyperBrowser. [From Simovski et al., 2017]
GSuite file format
Tabular file format for track metadata
The GSuite file format is metadata-centric tabular format for representing a collection, or suite, of track files. A GSuite file is able to bind together the whole chain of multi-track analysis, from search and retrieval of genomic tracks, through intermediate processing, to analysis.
The GSuite file format implements several useful properties (see also Figure 4.1):
List of URIs to represent a collection of track data files. In its simplest form, a GSuite
representing a collection of tracks can be represented as plain text file with one Uniform Resource
Identifier (URI) per line. Some IRI schemes, such as http, https, ftp, and rsync, refer to
remote locations for the actual track data files, while others, such as file and a few IRI
schemes custom to the GSuite format, implicitly refer to local storage of the track files.
Header variables. The GSuite format include a set of headers that contain summaries of certain aspects of the tracks in the collection, such as the reference genome, whether the tracks in the collection adhere to the same track type, and whether the included track files are available locally or remotely. These headers are useful for analysis and manipulation tools to easily determine whether the track collection is in the state required by the tool.
Title. Each track file can be assigned a title, which works as a unique identifier of each track in the context of the GSuite file and can be used in analysis tools for e.g. labeling charts or result outputs.
Custom metadata columns. Central to the concept of GSuite files is the ability to annotate the track files with metadata by adding columns, representing any metadata field, and in any order. Importantly, a GSuite file maintains the metadata alongside the data throughout the analysis. This allows the analysis tools to take advantage of metadata fields for e.g. parameter setting or for labeling output tables and graphs.
Simple tabular file format. Providing the track collection as a simple tabular file allows for
interoperability with a range of tools and scenarios, such as editing in a spreadsheet, manipulation
through command-line tools such as the UNIX tools sed and awk, or in a web framework such as
Galaxy. It also allows for easy parsing by analysis tools.
The combination of these properties allows GSuite files to be seamlessly exchanged between individual tools in an analysis workflow, as illustrated in Figure 4.2. In particular, the GSuite format has been designed to provide the following features:
Track search output. Tools and services for discovery of track files can provide a novel GSuite file as a response to a search query. Such a GSuite file would then typically contain URIs to original, remotely stored datasets, as well as related metadata. In the GSuite HyperBrowser, we implemented a first prototype of a track search tool based on metadata manually integrated from several data portals. However, the solution was not scalable due to the lack of a uniform metadata schema, which prompted the idea of a FAIRtracks metadata standard and the TrackFind service. A track search tool which works as a client towards the TrackFind REST API and exports GSuite files is now implemented in the GSuite HyperBrowser as part of the FAIRtracks project.
Manipulation of GSuite files. Since a GSuite file is a simple tabular file, further fine-tuning of a track collection can easily be carried out, such as filtering, splitting, joining, modification of metadata, etc.
Deferred download of track data. Since a GSuite file can refer to both remotely and locally located data files, one can easily defer the actual download of the data files until the track collections have been properly fine-tuned. A tool that downloads data referred to by a GSuite file can then iterate through the URIs, download each referred file, and replace the URIs with paths to the locally stored files. Similarly, the GSuite format allows for deferred preprocessing of data files into a binary format, such as BTrack, for tools that require this.
Galaxy integration. The GSuite format is supported in the GSuite HyperBrowser fork of Galaxy. We are working on adding support for GSuite in "vanilla" Galaxy instances. As part of the EOSC EuroScienceGateway project, we will also investigate whether GSuite can be integrated with RO-Crate as a general solution to maintaining metadata alongside datasets in Galaxy.
Figure 4.1: A few GSuite example files, illustrating core properties of the file format [detail from Figure 2.1, above]
Figure 4.2: Multi-track analysis flow built around the GSuite file format, as implemented in the GSuite HyperBrowser. [From Simovski et al., 2017]

Figure 5.1: Example BioXSD file containing track data
BioXSD/BioJSON/BioYAML (retired)
A unified data model for biomolecular sequences, features, alignments, references
BioXSD is a data model defining exchange formats for basic bioinformatics types of data: sequences, alignments, feature records with associated data and metadata. BioXSD aimed to serve as a common, canonical tree-structured format (XML, JSON, YAML, binary) for the basic bioinformatics data, filling the gap between more specialised tree-structured formats.
For Web Services. BioXSD is a rich but not too complicated data model and exchange format, aiming to enable deployment of globally and smoothly interoperable bioinformatics tools on the World Wide Web of Services. Tools can produce and consume BioXSD directly, or BioXSD can be used as an intermediate canonical format, rich enough to enable conversions among diverse formats. Using common exchange format enables smooth integration of compatible tools into analysis workflows.
Track types. BioXSD v1.1 added support for Track types as a tree-based alternative to GTrack, as illustrated in Figure 5.1.
Retirement. BioXSD was originally built as an XML schema, but support for other data-serialisation languages such as JSON, YAML is possible. In 2020 it was decided to retire the BioXSD format as part of the national services delivered by ELIXIR Norway. This was due to the decline of XML as a popular interchange format. Also, the bioinformatics community had not (yet) identified a need to define standardized JSON/YAML formats for sequence and annotation data, such as BioJSON / BioYAML. The data model can be resurrected in the future, if the need arises.
Figure 5.1: Example BioXSD file containing track data