![FAIRtracks-logo-light-white-320-[fixed].png](/_nuxt/img/6639f7d.png)

Figure 1.1: Overview of the FAIR Principles for research data. [From Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 3:160018 (2016), made available under the CC BY 4.0 license]

Figure 1.2: Important topics where the current state of track data and metadata have potential for improvements, as mapped to the FAIR data principles. [From Gundersen S et al. Recommendations for the FAIRification of genomic track metadata. F1000Research 2021, 10(ELIXIR):268]
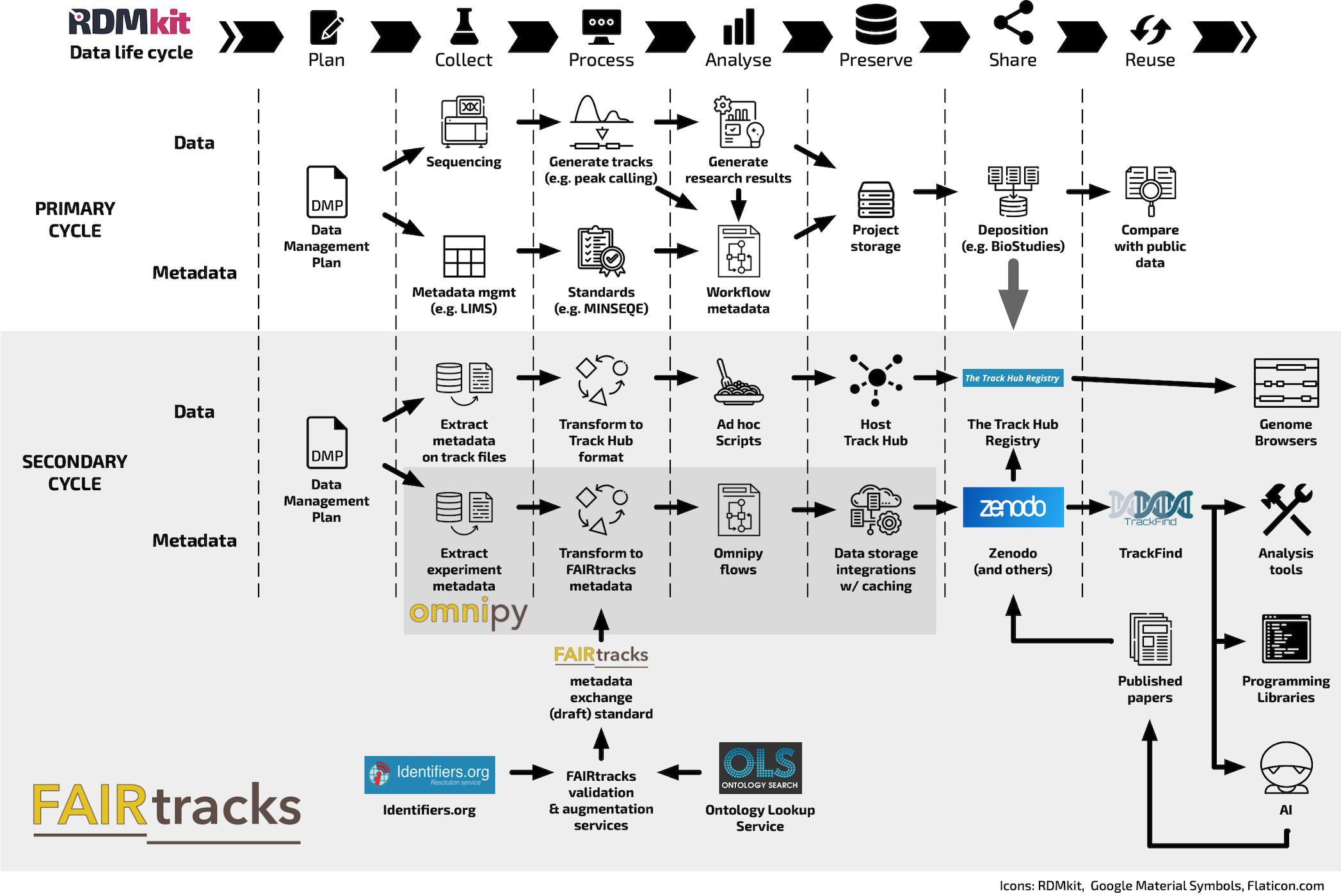
Figure 1.3: The secondary data life cycle in scope of the FAIRtracks project. Genomic track files are primarily deposited together with raw data and detailed metadata through the primary data life cycle. The secondary data life cycle supported by FAIRtracks is built around the FAIRtracks metadata (draft) standard, a minimal metadata exchange schema designed to refer back to the raw data/metadata if more details are required. The grey box shows the scope of the FAIRtracks project with current and potential integrations. Omnipy is a general Python library for scalable and reproducible data wrangling which aims to be useful across data models and research disciplines. (Illustration is planned for the RDMkit and is available for download from the Materials page)
FAIR data and FAIRtracks
Track data should be deposited in ways that allow for machine actionability, in line with the FAIR principles
The FAIR data principles provide technical guidelines to enable the Findability, Accessibility, Interoperability, and Reusability (FAIR) of research data. The main focus is on the machine-actionability of these aspects, i.e. the technical capability of performing these operations in an automatized way, with minimal human intervention.
Metadata. Metadata and metadata models play a major role in this process, and should contain:
- Global and persistent identifiers to datasets
- A number of attributes providing descriptive information about the context, quality, condition, and characteristics of the data
- Metadata attributes should be linked to controlled, shared vocabularies (or ontologies).
Identifiers and ontologies. To enable machine-actionability, the metadata needs to be indexed in a searchable resource and made retrievable via the identifiers using a standardized communication protocol. Moreover, a high level of standardization is required to achieve semantic interoperability allowing, e.g., for integration of different datasets. Linking metadata fields to ontologies provides context to the dataset as a self-describing information bundle where the links to ontologies provide the foundation to machine interpretation, inference, and logic.
Track data and FAIR principles. The degree to which deposited track data comply to the FAIR principles vary greatly, from near-perfect FAIRification practices in the context of certain consortia to the almost complete lack of metadata linked to track files in a range of smaller projects. Some common issues are listed in Figure 1.2. One of the major weaknesses is the lack of suitable uniform metadata schemas that can work across track collections. The lack of uniform metadata strongly limits the possibility of reusing or repurposing track data and hinders automation of these processes, especially when it comes to the "long arm" of deposited track data files. Furthermore, the lack of provenance information might introduce artefacts in the analyses. This lack of proper annotations and of a well-defined and universally adopted metadata standard is related to the lack of a central repository for track data, as described in the section Track collections.
![FAIRtracks-logo-transparent-180-[fixed].png](/_nuxt/img/1d83130.png)
The ambitions of the FAIRtracks project are two-fold:
-
Provide a set of pragmatic metadata schemas for genomic tracks that comply with the FAIR principles and are adopted and further developed by the community as a minimal metadata exchange standard, providing a unified view into both:
- novel track data depositions
- legacy track collections/data portals.
-
Provide a set of services to be integrated with downstream tools and libraries so that analytical end user can more easily discover and reuse from the massive amounts of track data that has been and is being created:
- for various species
- from different types of sample material
- by applying diverse types of experiment assays and in silico processing workflows.
See Figure 1.3 for an overview of the secondary data life cycle that falls within the scope of the FAIRtracks project.
Figure 1.1: Overview of the FAIR Principles for research data. [From Wilkinson, M. D. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 3:160018 (2016), made available under the CC BY 4.0 license]
Figure 1.2: Important topics where the current state of track data and metadata have potential for improvements, as mapped to the FAIR data principles. [From Gundersen S et al. Recommendations for the FAIRification of genomic track metadata. F1000Research 2021, 10(ELIXIR):268]
Figure 1.3: The secondary data life cycle in scope of the FAIRtracks project. Genomic track files are primarily deposited together with raw data and detailed metadata through the primary data life cycle. The secondary data life cycle supported by FAIRtracks is built around the FAIRtracks metadata (draft) standard, a minimal metadata exchange schema designed to refer back to the raw data/metadata if more details are required. The grey box shows the scope of the FAIRtracks project with current and potential integrations. Omnipy is a general Python library for scalable and reproducible data wrangling which aims to be useful across data models and research disciplines. (Illustration is planned for the RDMkit and is available for download from the Materials page)
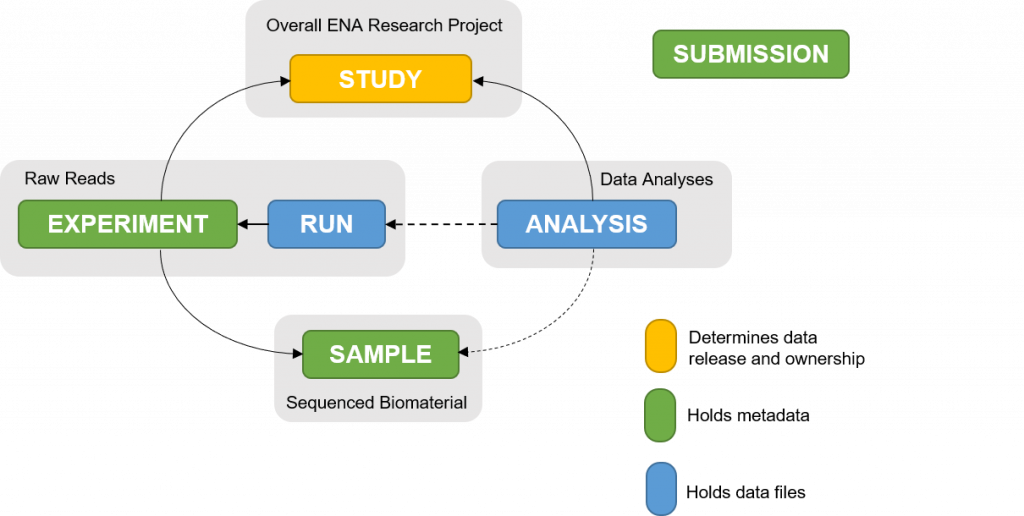
Figure 2.1: Overview of the metadata model of European Nucleotide Archive (ENA), which has evolved from the INSDC data model. [From the ENA web site, available under the CC BY 4.0 license]
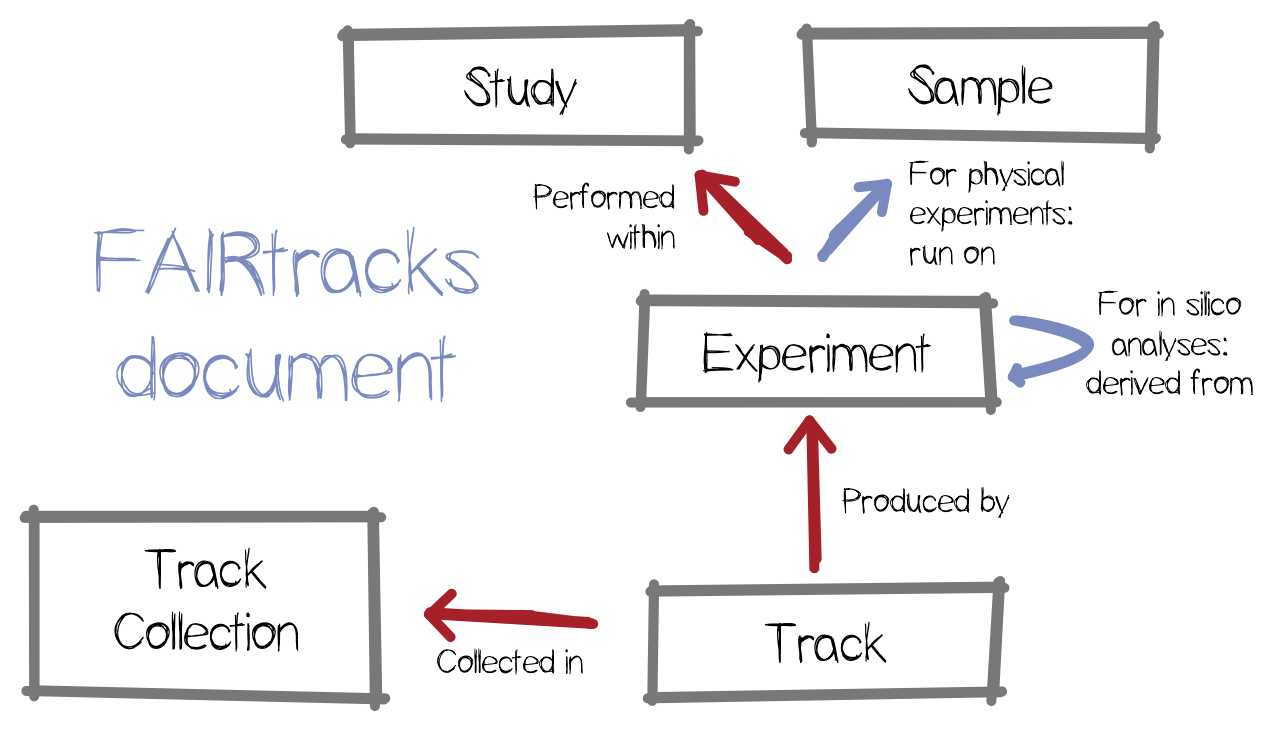
Figure 2.2: Overview of the key objects in the FAIRtracks metadata standard. A "track" is an atomic element representing a genomic track data file. Each "track" is generated by an "experiment", physically or in silico. Physical "experiments" link out to "samples". Sets of "experiments" are contained within a "study" object. Finally, "tracks" are grouped into "track collections", which directly matches the existing track hub object. A "track collection" can also refer to an ad hoc collection of tracks, e.g., documenting the input data of published analyses. [From Gundersen S et al. Recommendations for the FAIRification of genomic track metadata. F1000Research 2021, 10(ELIXIR):268]
Track Metadata Models
Metadata models used to describe track data should be interoperable with other models commonly used to describe genomic datasets
INSDC. Many of the metadata models for annotation of genomic datasets available today evolved from INSDSeq. INSDSeq is the official supported XML format of the International Nucleotide Sequence Database Collaboration (INSDC), a long-standing foundational initiative that operates between NCBI (in the USA), EMBL-EBI (in the UK) and DDBJ (in Japan) to facilitate genomic data exchange. The INSDSeq standard proposes the assignment of a number of interlinked metadata objects to each data file, the most relevant among these being “Experiment”, “Study”, and “Sample”. Modern implementations of this model are the European Nucleotide Archive (ENA) metadata model and the Sequence Read Archive (SRA) schemas (see Figure 2.1).
ISA. The Investigation Study Assay (ISA) metadata framework provides a flexible solution for rich description and annotation of experimental outputs. The ISA abstract model exhibits a hierarchical nested structure comprising the "Investigation", "Study", and "Assay" metadata categories. The ISA model is implemented in tabular, JSON and Resource Description Framework (RDF) formats and is supported by dedicated software, ISA tools.
Table 2.1 lists these and other well-developed data models in use for genomic track data.
Objects. Developed in relation to these data models and others, the FAIRtracks data model is based on five key objects: Track collection, Study, Sample, Experiment, and Track. The relationships between the objects are illustrated and explained in Figure 2.2, while the mapping of the FAIRtracks objects to other data models are shown in Table 2.2.
Metadata fields. The additional attributes for each object type in FAIRtracks have been defined by striking a compromise between the work imposed on the producer and the consumer of the metadata. As a result, the mandatory attributes are only the ones that appeared necessary for generic re-analysis of the data. Notably, these fields also include resolvable references to relevant existing metadata records in external resources, in compliance with the FAIR data principles (see above).
Figure 2.1: Overview of the metadata model of European Nucleotide Archive (ENA), which has evolved from the INSDC data model. [From the ENA web site, available under the CC BY 4.0 license]
Figure 2.2: Overview of the key objects in the FAIRtracks metadata standard. A "track" is an atomic element representing a genomic track data file. Each "track" is generated by an "experiment", physically or in silico. Physical "experiments" link out to "samples". Sets of "experiments" are contained within a "study" object. Finally, "tracks" are grouped into "track collections", which directly matches the existing track hub object. A "track collection" can also refer to an ad hoc collection of tracks, e.g., documenting the input data of published analyses. [From Gundersen S et al. Recommendations for the FAIRification of genomic track metadata. F1000Research 2021, 10(ELIXIR):268]
| Originator | Description | Standard file format | Standard description | Databases/Dataportals | Notes |
|---|---|---|---|---|---|
| Nucleotide Sequence Database Collaboration (INSDC) | Long-standing foundational initiative that operates between NCBI, EMBL-EBI and DDBJ to facilitate genomic data exchange. | XML | Modern implementations of this model are the ENA metadata model and the Sequence Read Archive (SRA) schemas. | NCBI, EMBL-EBI and DDBJ | |
| International Human Epigenome Consortium (IHEC) | Organization aiming at coordinating the production of reference maps of human epigenomes. | XML | Extended from SRA described at GitHub repo. | BLUEPRINT and ENCODE | IHEC data portal |
| Functional annotation of animal genomes (FAANG) | Consortium to discover basic functional knowledge of genome function to decipher the genotype-to-phenotype (G2P) link in farmed animals. | Inherited from hosting plateform (BioSamples, EBI, ENA SRA, NCBI, ArrayExpress or ENA) | The FAANG metadata model supports the MIAMEand MINSEQE guidelines. | FAANG data portal | Use ontology Experimental Factor Ontology (EFO) and the ontologies it imports. |
Table 2.1: Description of the main metadata models relevant for life science data. Please report any errors or omissions to our GitHub repo as an issue, or provide a PR.
| FAIRtracks | INSDC | ISA | Track Hub Registry | GSuite |
|---|---|---|---|---|
| Track collection | Submission (SRA) & Dataset (ENA) | Investigation | Track Hub | Track collection |
| Study | Study | Study | ||
| Sample | Sample | Sample | ||
| Experiment | Experiment & Analysis | Assay & Process | ||
| Track | Analysis | Data | Track | Track |
Table 2.2: Mapping of objects in the FAIRtracks metadata standard to objects in other metadata standards. [Adapted from Gundersen S et al. Recommendations for the FAIRification of genomic track metadata. F1000Research 2021, 10(ELIXIR):268]
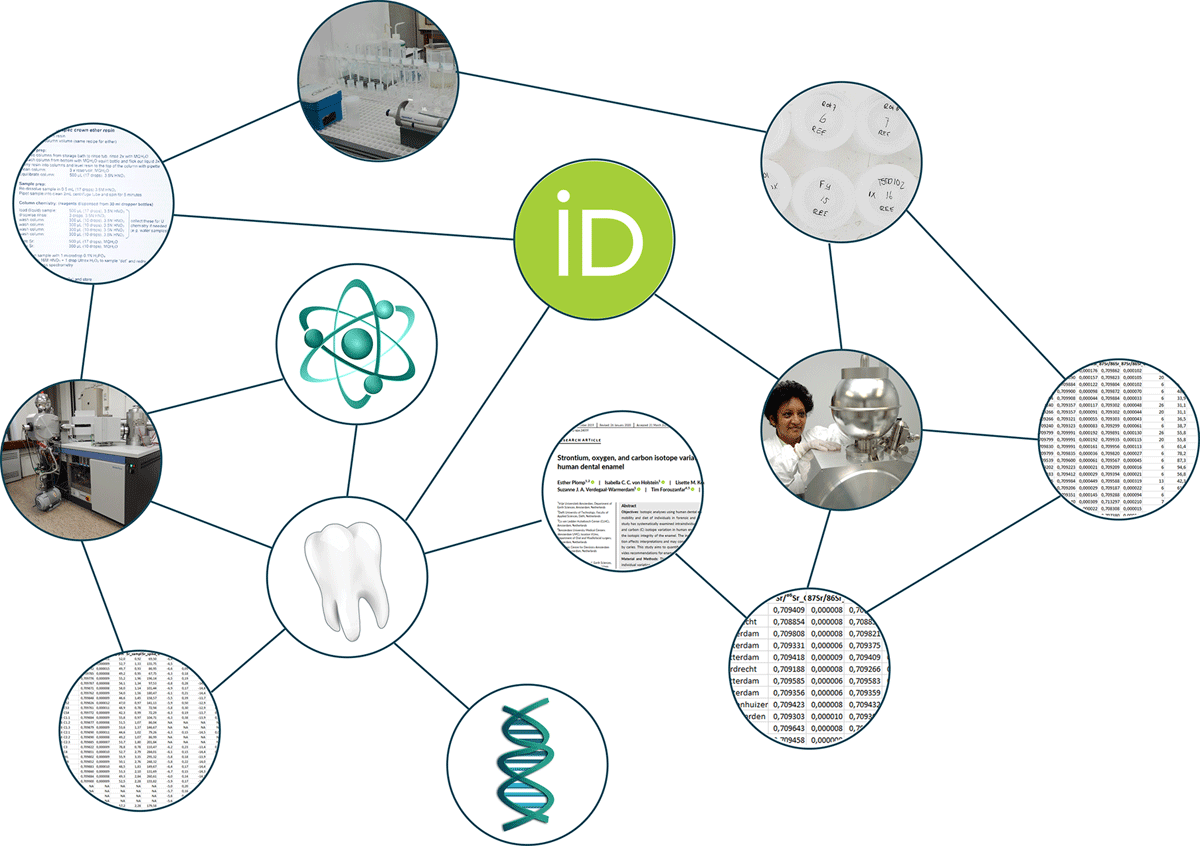
Figure 3.1: Globally unique and persistent identifiers allow linking research data with different aspects of the research environment, such as physical samples, experiment setup, in silico analyses, studies, and publications. [From Plomp, E., 2020. Going Digital: Persistent Identifiers for Research Samples, Resources and Instruments. Data Science Journal, 19(1), p.46, made available under the CC BY 3.0 license.]
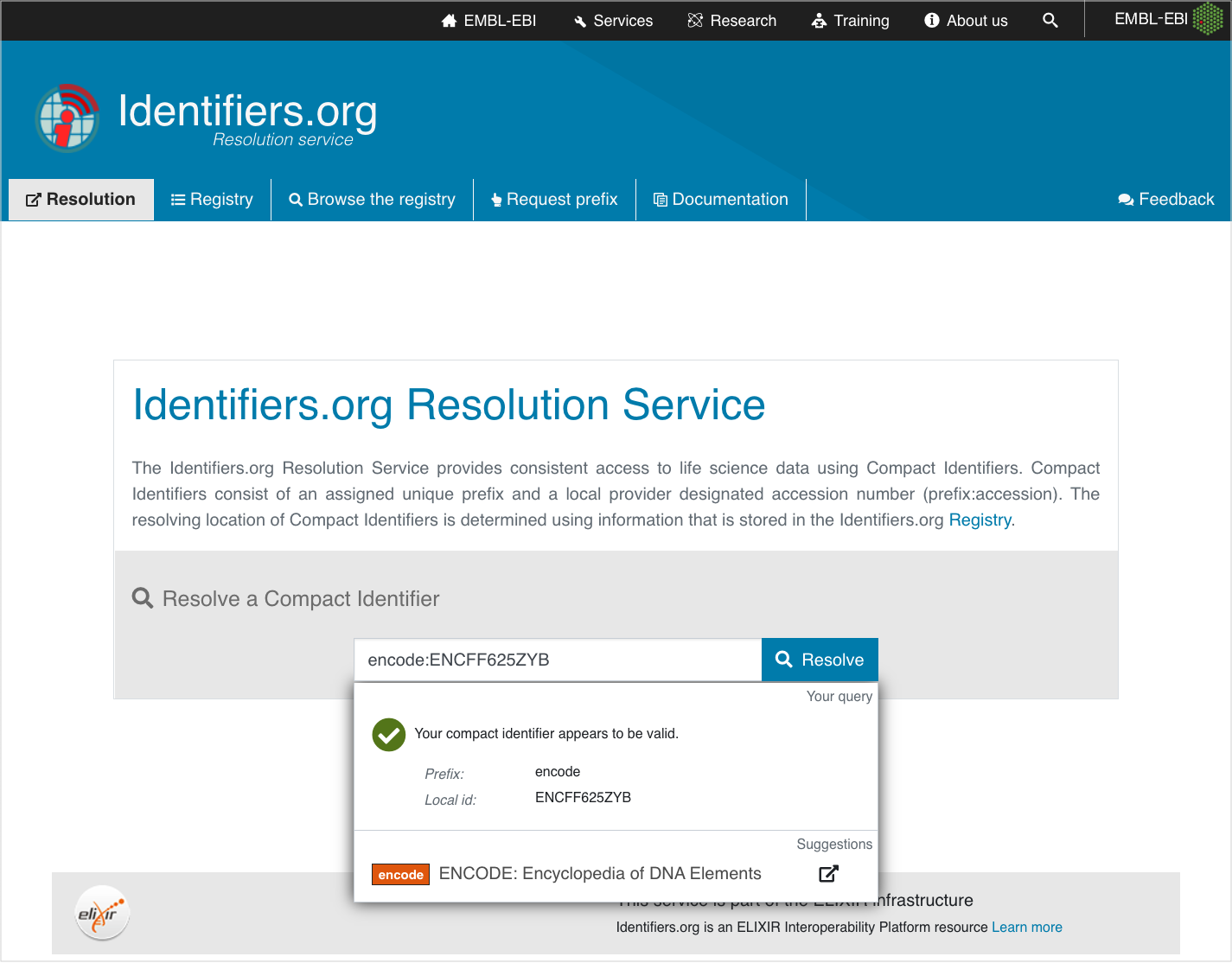
Figure 3.2: Screenshot from the ELIXIR-supported Identifiers.org, which resolves globally unique and persistent identifiers in the form of CURIEs and returns URLs to repository web pages containing information about the referred object. Identifiers.org is a partner of the US-based Names to things (N2T.net), which provides similar services.
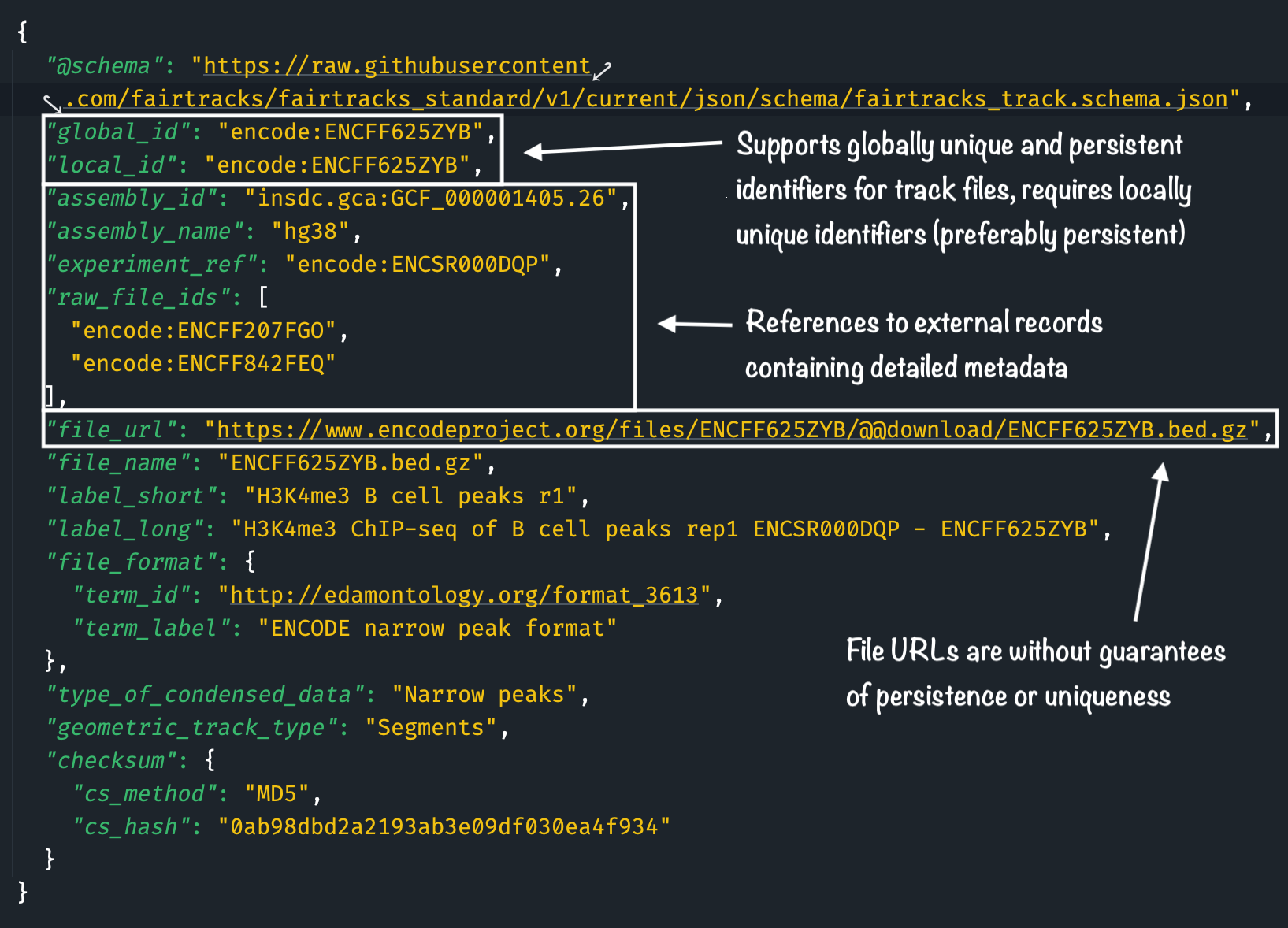
Figure 3.3: Example track record according to the "Track" sub-schema of the FAIRtracks metadata standard. Highlighted are the fields for globally unique and persistent identifiers, locally unique identifiers, some references to external records, as well as track file URLs.
Identifiers
Assign a persistent reference to your published track data
FAIR principle F1 stipulates the need to assign identifiers to data and metadata that are both 1)
globally unique and 2) persistent. The
GO FAIR website page on the topic
further asserts:
Principle F1 is arguably the most important because it will be hard to achieve other aspects of FAIR without globally unique and persistent identifiers.
Globally unique and persistent identifiers allows the linking of research data with different aspects of the research environment (Figure 3.1).
The need for track file identifiers: Track data files are seldom assigned identifiers directly; often it is only the raw sequence files used to generate the track files that are assigned identifiers, typically the accession numbers to data repositories such as the Sequence Read Archive (SRA) or the European Genome-Phenome Archive (EGA). The ENCODE project represents a notable exception: each track is associated with an identifier resolvable through Identifiers.org (see Figure 3.2) and a dedicated web page. Furthermore, a universally accessible service to assign and register identifiers to single track files and collections is currently missing.
We therefore strongly recommend the implementation of a track registry
Track files contain condensed data from bioinformatics workflows and are thus dependent on specific parameter settings and cannot be perfectly recreated from the raw without also perfectly reproducing the full analysis workflow, which is often a difficult task. We therefore strongly recommend the implementation of a track registry that preserves the full context of tracks by assigning global identifiers not only to the track data files but also to the associated metadata.
Built for track file identifiers: The FAIRtracks draft standard is developed from the ground up to support globally unique and persistent identifiers for track files and could be suitable for use as a basis for a potential global registry of track metadata (see Figure 3.3). For now, global track identifiers are allowed, but not enforced by the FAIRtracks standard. Instead, we require the inclusion of local track identifiers within the dataset as well as Uniform Resource Locators (URLs) to track files, which, unfortunately, come without any guarantees of persistence or uniqueness. The FAIRtracks standard still provides globally unique and persistent identifiers to track files in an indirect manner, using document DOIs.
DOI as document identifier: In case a direct identifier is not attached to a track file, the identifier of a parent record (e.g. study or experiment) can be used instead. On top of this, FAIRtracks requires a global identifier for the metadata file itself using a document identifier (DOI). In principle, a track file can thus be uniquely pinpointed by a joint identifier containing the DOI of the FAIRtracks document and the locally unique track identifier. As our policy requires support for DOI versioning and DOI reservation prior to publication, we currently recommend Zenodo for publishing FAIRtracks documents. We would extend our list of recommended repositories and archives to any domain-specific services meeting our requirements.
"Mix-tape" track collection identifiers: Apart from the main use case of annotating primary track collections deposited in some repository, FAIRtracks is designed to also allow a more novel use case: to annotate secondary "mixtape" track collections of track files originating from different primary sources. The main example of this use case is to annotate the exact track data files used to generate the findings of a scientific publication, whether these track files represent novel data, are directly reused from other repositories, are regenerated from the raw data or in other ways derived from the original track files. To allow the provenance of such "mixtape" reuse of tracks, assigning globally unique and persistent identifiers to track collections would be advantageous. Full support for secondary track collections is scheduled for version 2 of the FAIRtracks standard (coming soon). Currently, this concept is most fully developed in the form of GSuite files in the context of the GSuite HyperBrowser.
References to external records: FAIRtracks supports and recommends the inclusion of global identifiers to external records containing detailed metadata. We require these global identifiers represented in Compact Uniform Resource Identifies (CURIE) form resolvable through Identifiers.org (see Figures 3.2 and 3.3). A mapping service from existing URIs to the corresponding CURIEs is desirable, as it would enhance the conversion of existing metadata to the FAIRtracks standard.
Figure 3.1: Globally unique and persistent identifiers allow linking research data with different aspects of the research environment, such as physical samples, experiment setup, in silico analyses, studies, and publications. [From Plomp, E., 2020. Going Digital: Persistent Identifiers for Research Samples, Resources and Instruments. Data Science Journal, 19(1), p.46, made available under the CC BY 3.0 license.]
Figure 3.2: Screenshot from the ELIXIR-supported Identifiers.org, which resolves globally unique and persistent identifiers in the form of CURIEs and returns URLs to repository web pages containing information about the referred object. Identifiers.org is a partner of the US-based Names to things (N2T.net), which provides similar services.
Figure 3.3: Example track record according to the "Track" sub-schema of the FAIRtracks metadata standard. Highlighted are the fields for globally unique and persistent identifiers, locally unique identifiers, some references to external records, as well as track file URLs.
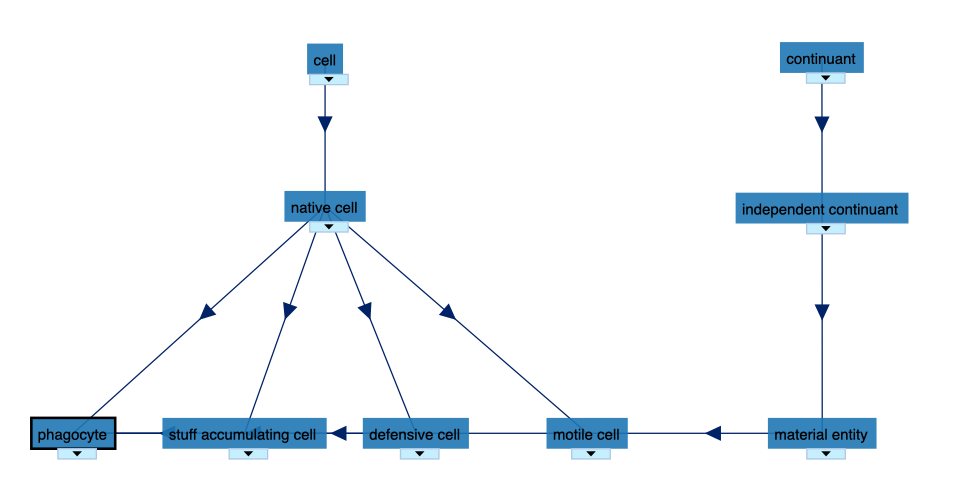
Figure 4.1: Example ontology term from the Cell Ontology: The cell type phagocyte is represented by a term (or concept) with a description, a persistent unique identifier (PID) (here Concept ID) and relationships (see also Figure 4.3). The current figure shows the other terms that are direct or indirect ancestors of phagocyte: native cell, motile cell, - defensive cell, and stuff accumulating cell, all the way to the top-level terms. As can be gathered from the illustration, the same concept phagocyte is inserted several places in the hierarchy simultaneously, uniquely referenced by its PID in all relationships. Numerous descendants of the term phagocyte exist, but are not shown in the illustration. [The visualization has been fetched from the NCBO BioPortal]

Figure 4.2: Examples of domain knowledge represented as generously annotated relationships connecting the Gene Ontology term phagocytosis to other terms in the context of the Cell Ontology. [From Ontobee: "phagocytosis" in Cell Ontology. See also Figure 4.3]
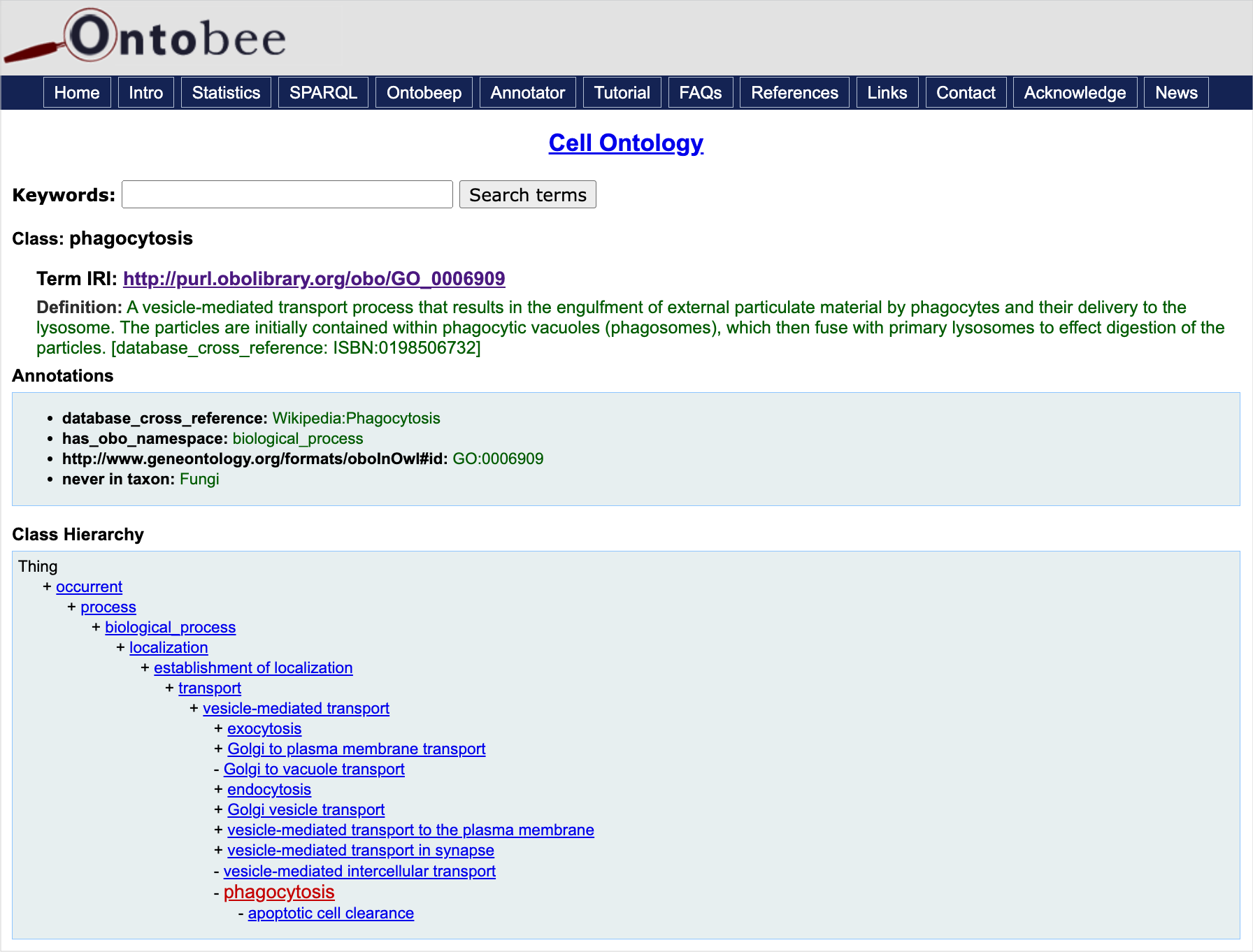
Figure 4.3: The Gene Ontology term phagocytosis merged into the Cell Ontology. [From Ontobee: "phagocytosis" in Cell Ontology]
Ontologies
Formal ontologies should be used for biological terms to provide context to the metadata
An ontology is a "representation of the shared background knowledge for a community" (Stevens, Rector & Hull, 2010). More than just a controlled vocabulary, an ontology provides a formal conceptualization of the nature and structure of the objects it refers to (Guarino, 2006). The ontology terms have formal definitions and relationships and are typically arranged hierarchically in the main structure, as illustrated with the term phagocyte in Figure 4.1. Each ontology term is assigned a persistent unique identifier (PID) which enables interoperability across datasets, services, repositories, and ontologies.
Linking terms across ontologies: Interoperability of biological terms across ontologies by the use of PIDs is invaluable for describing complex biological knowledge with composite annotations. Expanding the example from Figure 4.1, we see in Figure 4.2 that the phagocyte cell type in the Cell Ontology is linked to the biological process phagocytosis as described in the Gene Ontology through the relation:
phagocyte subClassOf: capable of some phagocytosis
On a technical level, this relationship has been allowed through the addition of the PID of the Gene Ontology-term phagocytosis as a foreign ID to the Cell Ontology (Figure 4.3).
Registries of ontologies:
- The most relevant ontologies are registered and accessible through the Ontology Lookup Service (OLS) and the NCBO BioPortal. These services allow for lookup of terms across multiple ontologies and provide support for ontology discovery based on a limited set of metadata fields.
- The OBO foundry community provides access to a set of interoperable ontologies that are both logically well-formed and scientifically accurate, following these sets of principles.
- FAIRsharing annotates ontologies with richer metadata and provides lists of related records, including standards and databases. For these reasons, FAIRsharing is a valuable tool for discovering ontologies by assessing their use in the communities.
One concept – one term! In order to provide a clean and simple interface to the end users, FAIRtracks aims to map each concept to one and only one ontology term. To this end, the ontologies have been carefully selected and organized in such a way that the domains do not overlap. Table 4.1 lists the ontologies, controlled vocabularies and databases used in the latest version of the FAIRtracks metadata standard.
Composite fields: Core biological ontologies are often overlapping considerably domain-wise, not
least due to the widespread practice of importing parts of other ontologies (as exemplified in
Figure 4.3). However, most ontologies have certain branches or subdomains where they are
particularly strong. In FAIRtracks we take advantage of this by splitting a few of the most
important fields, in particular the fields experiment.target and sample.sample_type, into more
precise subfields. Each subfield is then linked to a specific branch of a specific ontology which is
particularly strong in that subdomain.
Summary fields: Many subfields are only relevant to certain types of records and will thus have
missing values elsewhere. To counteract this we provide the general fields
experiment.target.summary and sample.sample_type.summary that are automatically generated based
on logic particular to each type of record (see section Augmentation
below). End users and downstream software can then opt to ignore the subfields (as the values might
be missing or might be too detailed) and instead depend only on the summary fields. The FAIRtracks
standard (in its augmented form) guarantees that the values of the summary fields are present across
all types of experiments and samples.
Community influence on ontology choices: When we developed the FAIRtracks standard in the context of the initial ELIXIR Implementation study, ontologies were chosen based on perceived quality as well as community uptake. The selection was however also, to a certain extent, a subjective process. If you have opinions on the ontology choices, please join us as an early adopter to make your voice heard (see the Community page)!
Figure 4.1: Example ontology term from the Cell Ontology: The cell type phagocyte is represented by a term (or concept) with a description, a persistent unique identifier (PID) (here Concept ID) and relationships (see also Figure 4.3). The current figure shows the other terms that are direct or indirect ancestors of phagocyte: native cell, motile cell, - defensive cell, and stuff accumulating cell, all the way to the top-level terms. As can be gathered from the illustration, the same concept phagocyte is inserted several places in the hierarchy simultaneously, uniquely referenced by its PID in all relationships. Numerous descendants of the term phagocyte exist, but are not shown in the illustration. [The visualization has been fetched from the NCBO BioPortal]
Figure 4.2: Examples of domain knowledge represented as generously annotated relationships connecting the Gene Ontology term phagocytosis to other terms in the context of the Cell Ontology. [From Ontobee: "phagocytosis" in Cell Ontology. See also Figure 4.3]
Figure 4.3: The Gene Ontology term phagocytosis merged into the Cell Ontology. [From Ontobee: "phagocytosis" in Cell Ontology]
| Schema | Field | Ontology | Ancestor terms | Comments |
|---|---|---|---|---|
| experiment | technique | The Ontology for Biomedical Investigation (OBI) | planned process | |
| experiment | technique | EDAM | Operation | |
| experiment | target.sequence_feature | The Sequence Ontology (SO) | sequence_feature | |
| experiment | target.gene_id | HUGO Gene Nomenclature Committee (HGNC) | CURIEs in the "hgnc" namespace | |
| experiment | target.gene_product_type | The National Cancer Institute Thesaurus (NCIt) | Gene product |
Table 4.1: Ontologies, databases, and controlled vocabularies used in v1.0.2 of the FAIRtracks metadata standard, ordered by FAIRtracks schema/field name. If ancestor terms are specified, only terms that are somehow descending from the ancestor terms are allowed, effectively limiting the domain of the field to particular sub-branches of particular ontologies.
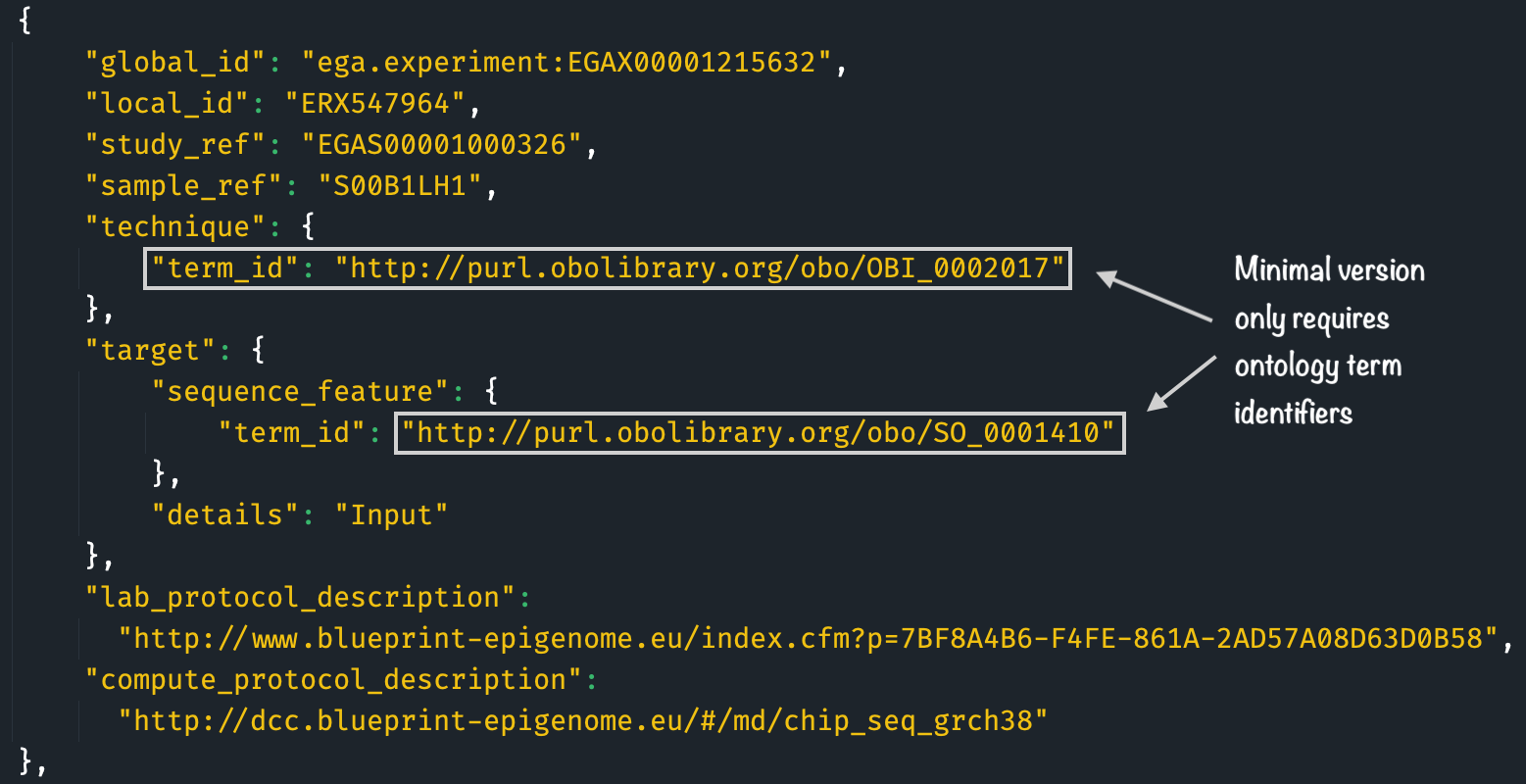
Figure 5.1: Example of minimal FAIRtracks metadata record adhering to the Experiment schema. Only the identifiers are included to represent the ontology term values of the fields technique and target.sequence_feature. [Extracted from the minimal version of the FAIRtracks-aligned BLUEPRINT metadata document]
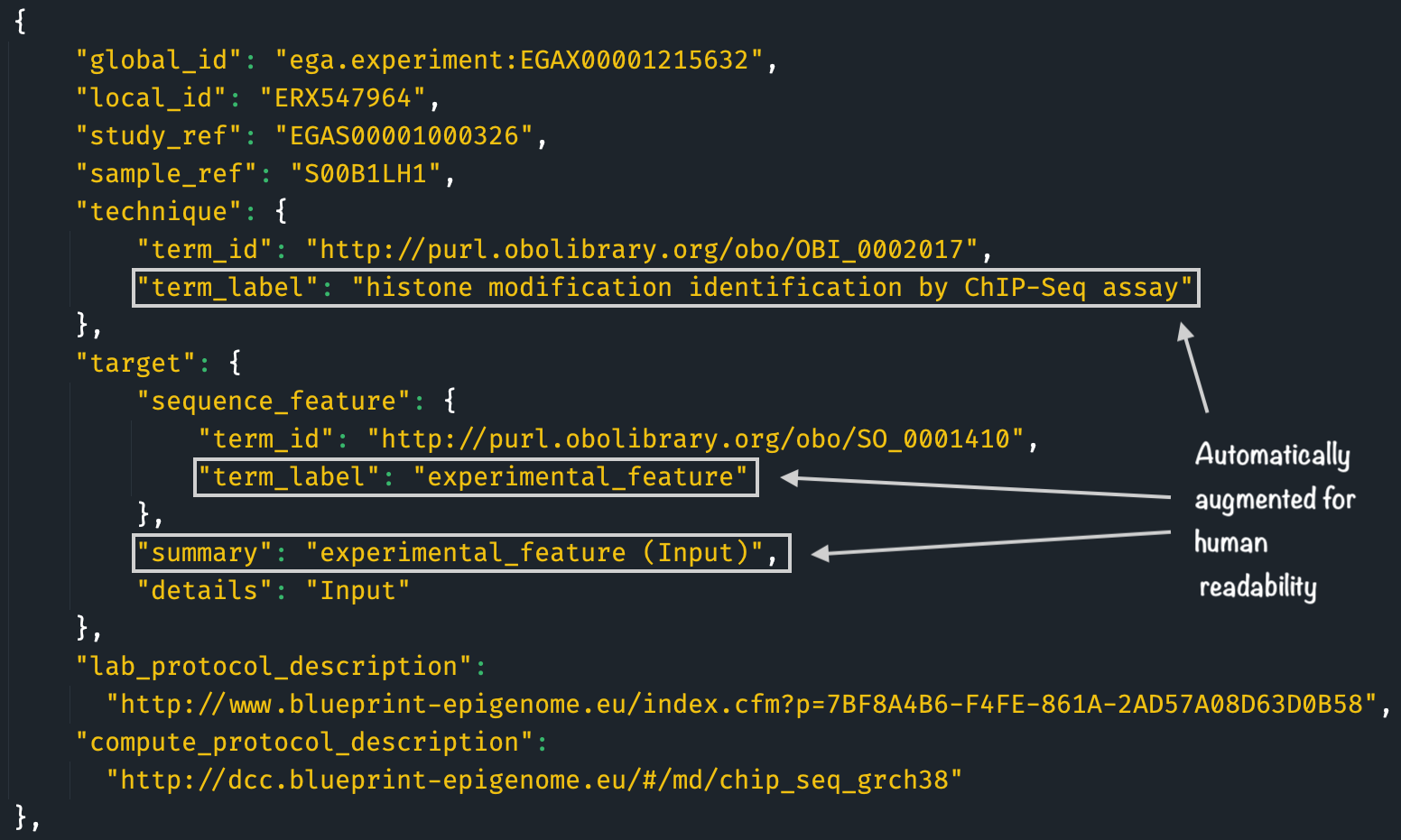
Figure 5.2: Example of augmented FAIRtracks metadata record adhering to the Experiment schema. The ontology term identifiers have been mapped to human-readable labels according to the latest version of the ontologies. Additionally, the field target.summary have been automatically filled based on the contents of fields technique.term_id, target.sequence_feature.term_label and target.details. [Extracted from the augmented version of the FAIRtracks-aligned BLUEPRINT metadata document]
Augmentation
Automated power-up of metadata to improve human interaction
We developed the FAIRtracks metadata standard and the associated ecosystem of services with the aim of fulfilling two main objectives:
-
To facilitate deposition of novel track data and unification of metadata from legacy track collections in compliance with the FAIR data principles.
-
Improving downstream reuse of track data through services for data discovery and retrieval applied to unified and FAIR metadata.
Metadata for data providers vs end users: In the initial development phase we quickly discovered that these two objectives are somewhat at odds with each other. Downstream users will typically prefer strict, homogeneous, and human-readable metadata. Data providers, on the other hand, will typically prefer streamlined deposition, variation in metadata content, and machine-operable metadata.
Human-readable labels for ontology terms? This gap can be illustrated in the case of ontology terms. If data providers were to only provide the machine-operable identifiers for the terms, human users will not be able to directly understand them. Furthermore, it would be cumbersome for downstream developers and analytical end users to have to implement ontology lookup functionality in order to make use of the metadata. On the other hand, forcing data providers to provide both identifiers and human-readable labels for all ontology terms would discourage data deposition.
Bridging the gap: Based on the above considerations and similar examples, we discovered a need for intermediate solutions that provide ontology lookup functionality and other FAIR-oriented features to help bridge this gap:
Minimal and augmented versions of FAIRtracks: Data providers that adopt the FAIRtracks metadata standard only need to fill the minimal set of fields that are marked as "required", which together constitutes the minimal version of the FAIRtracks standard (see Figure 5.1). The FAIRtracks augmentation service is implemented as a REST API that takes a minimal FAIRtracks-compliant JSON document as input, adds a set of fields with human-readable values to the document, and provides this augmented FAIRtracks-compliant JSON document as output. The fields added include human-readable ontology labels, ontology versions, human-readable summary fields, and other pragmatic fields useful for interactions with the end user (see Figure 5.2). This service simplifies the job on the data providers side and, at the same time, improves the quality of the data discovery and retrieval operations on the users' side in both automated and manual usage scenarios.
Figure 5.1: Example of minimal FAIRtracks metadata record adhering to the Experiment schema. Only the identifiers are included to represent the ontology term values of the fields technique and target.sequence_feature. [Extracted from the minimal version of the FAIRtracks-aligned BLUEPRINT metadata document]
Figure 5.2: Example of augmented FAIRtracks metadata record adhering to the Experiment schema. The ontology term identifiers have been mapped to human-readable labels according to the latest version of the ontologies. Additionally, the field target.summary have been automatically filled based on the contents of fields technique.term_id, target.sequence_feature.term_label and target.details. [Extracted from the augmented version of the FAIRtracks-aligned BLUEPRINT metadata document]
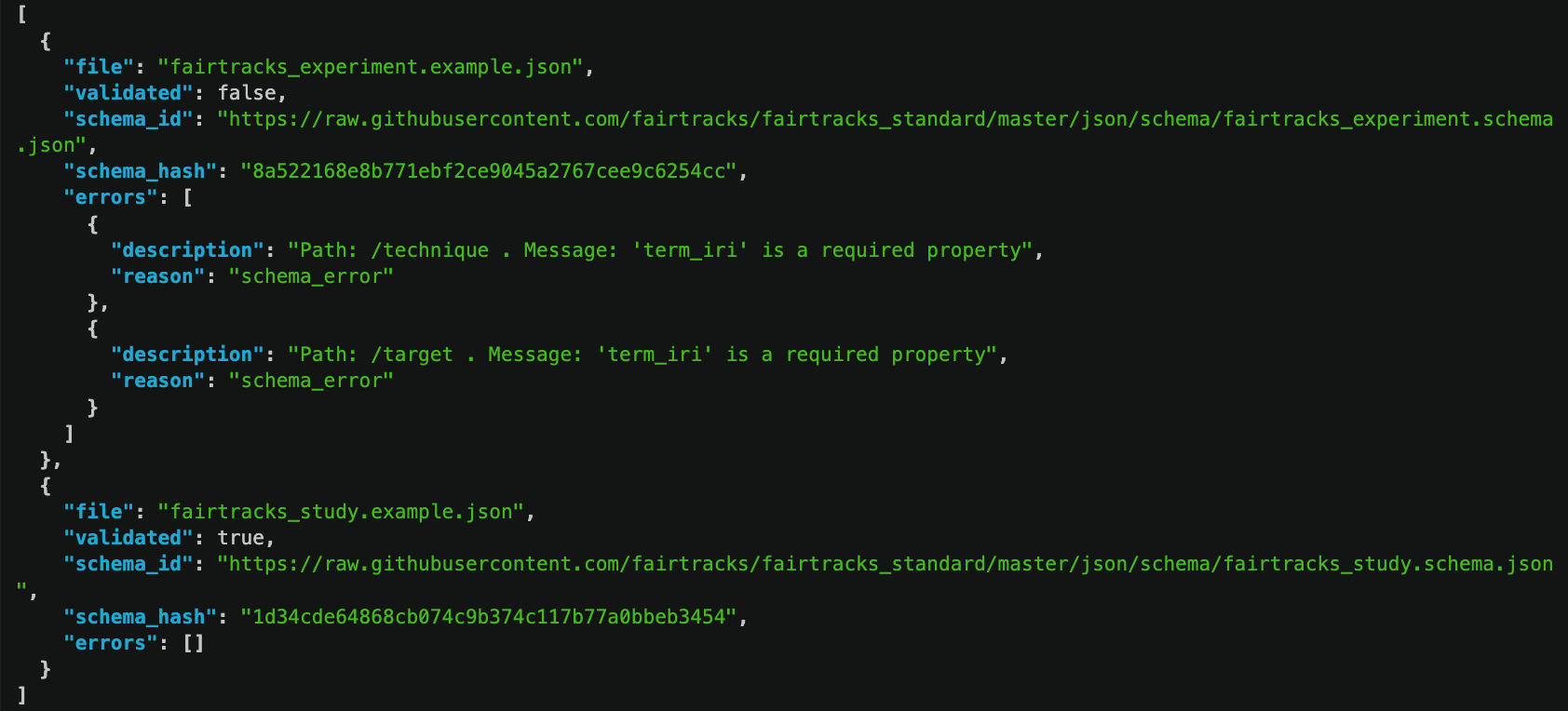
Figure 6.1: Output from the FAIRtracks validation service showing two validation errors: The record lacks ontology terms for two of the required fields. [From the "FAIRtracks validator - Using REST API from command line" screencast]
Tech note #1:
Managing ontology versions
Pinning ontology versions is problematic
Our initial working idea was to pin a list of specific ontology versions to each version of the FAIRtracks standard, much like how a dependency lock file is used in a software package manager. This would ensure consistent validation over time. However, such a solution is not sustainable, as it would require constant updates of the standard to keep pace with the releases of new ontology versions.
Using the most recent ontology versions is less problematic
Only depending on the most recent ontology versions makes validation less stable, as ontology updates can cause a document to suddenly fail validation. FAIRtracks metadata documents should thus be automatically re-validated whenever new ontology versions are released. This also assures continued interoperability of FAIRtracks services with third-party services that are dependent on the same ontologies. If there is a need to debug sudden validation failures, it should also come in handy that the augmentation process annotates the FAIRtracks documents with the exact ontology versions used for lookup.
Technical note #1: Our arguments why depending on only the most recent version of each ontology is less problematic than pinning the ontology versions.
Validation
Automated validation of your metadata documents
Standards and validators: An important aspect of any kind of standardization is to define mechanisms for validating adherence to the standard. Such validation should be precise and thorough enough to uphold the required level of quality, while at the same time not be too much of a burden for adopters. In the domain of interoperable web services, the de facto standard is to deploy an HTTP-based API that follows some level of RESTfulness. The de facto standard for data representation is JSON documents, and the de facto standard that allows for annotation and validation of JSON documents is JSON Schema.
JSON Schema: Syntactically, a JSON Schema is just a JSON document that makes use of a standardized vocabulary and structure, as defined in a particular version of the JSON Schema specification. JSON Schemas are used to describe JSON data formats by describing a set of restrictions to the content and structure of JSON documents. These restrictions are typically upheld by a particular authority, such as a metadata standard or a REST API. An important property of a JSON Schema document is that it is both human-readable and machine-actionable. JSON Schema validators are available in most programming languages, simplifying the process of automatic validation of JSON documents according to the respective JSON Schemas.
FAIRtracks validator: The FAIRtracks metadata standard is implemented as a set of JSON Schemas, following the above-mentioned de facto standards for interoperable web services (see Figure 6. 1). Use of JSON Schema provides a way to formalize restrictions that can easily be machine-validated. We provide the FAIRtracks validation service to allow data providers to verify the adherence of JSON metadata documents towards the FAIRtracks metadata standard.
Features: The FAIRtracks validator extends standard JSON Schema validation technology through additional modules that allows for:
- Validation of ontology terms against specific ontology versions
- Checking CURIEs against the registered entries at the Identifiers.org resolution service
- Checking restrictions on a full set of documents, e.g. whether identifiers are unique across all documents and whether the records referred to by foreign keys actually exists.
Managing ontology versions: To our knowledge, there is no consensus of how to relate versions of metadata schemas with versions of the ontologies they depend on. For FAIRtracks standard, as well as the augmentation and validation services, we decided to only relate to the most recent version of each ontology. Our reasoning behind this choice is detailed in Technical note #1 (to the side). If you know more about this than we do, please let us know!.
Figure 6.1: Output from the FAIRtracks validation service showing two validation errors: The record lacks ontology terms for two of the required fields. [From the "FAIRtracks validator - Using REST API from command line" screencast]
Tech note #1:
Managing ontology versions
Pinning ontology versions is problematic
Our initial working idea was to pin a list of specific ontology versions to each version of the FAIRtracks standard, much like how a dependency lock file is used in a software package manager. This would ensure consistent validation over time. However, such a solution is not sustainable, as it would require constant updates of the standard to keep pace with the releases of new ontology versions.
Using the most recent ontology versions is less problematic
Only depending on the most recent ontology versions makes validation less stable, as ontology updates can cause a document to suddenly fail validation. FAIRtracks metadata documents should thus be automatically re-validated whenever new ontology versions are released. This also assures continued interoperability of FAIRtracks services with third-party services that are dependent on the same ontologies. If there is a need to debug sudden validation failures, it should also come in handy that the augmentation process annotates the FAIRtracks documents with the exact ontology versions used for lookup.
Technical note #1: Our arguments why depending on only the most recent version of each ontology is less problematic than pinning the ontology versions.
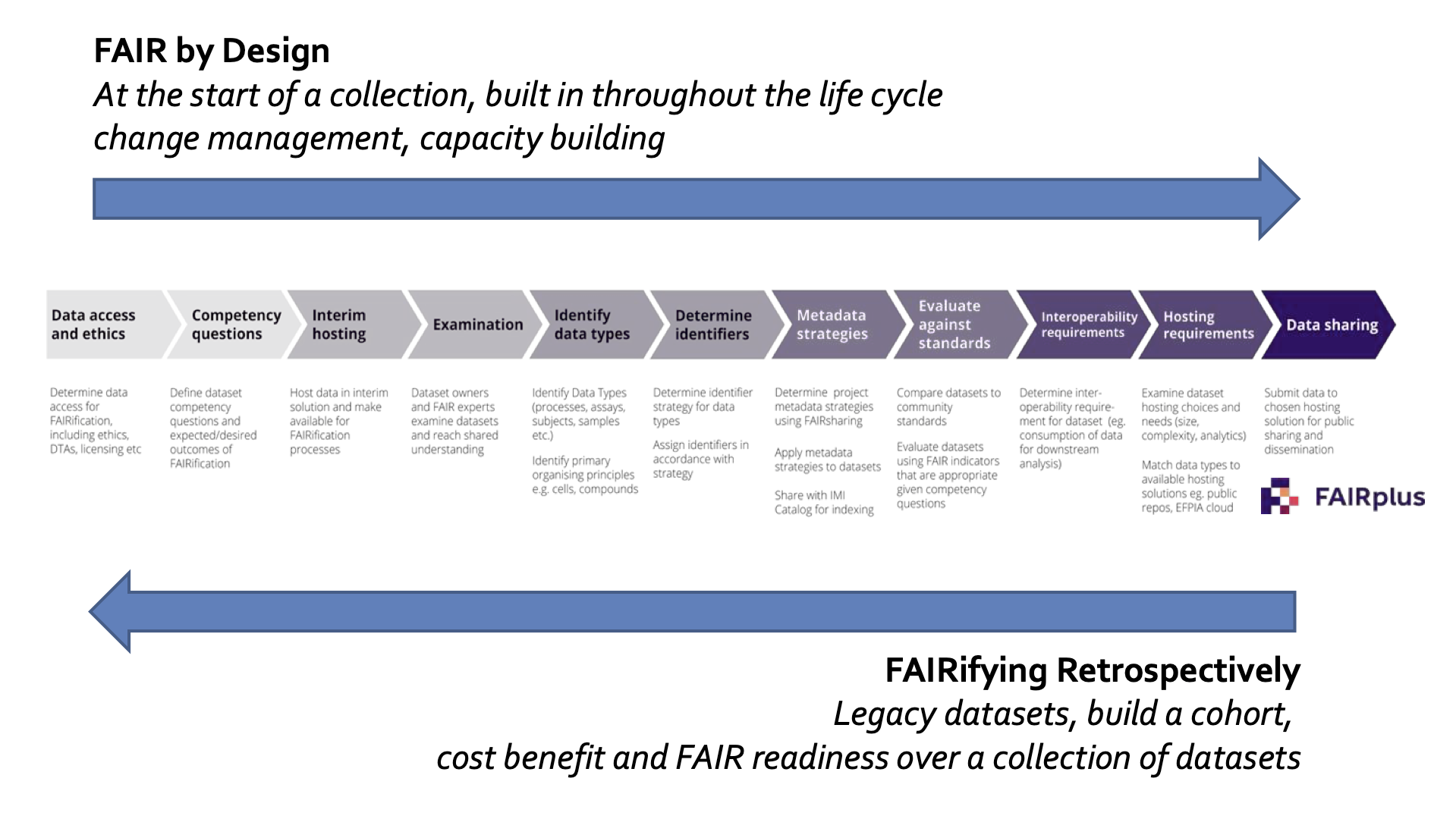
Figure 7.1: The difference between making research (meta)data "FAIR by Design" from the outset and "FAIRifying Retrospectively". [From Goble, Carole: How are we Faring with FAIR? (and what FAIR is not). FAIRe Data Infrastructures, 15 October 2020. License: CC BY 4.0]
Tech note #2:
Parse, don't validate
Type-driven design
This alternative approach to data wrangling is summed up in a slogan coined by Alexis King in 2019 in an influential blog post: "Parse, don't validate". King here argues for the use of "Type-driven design", also called "Type-driven development":
Type-driven development is a style of programming in which we write types first and use those types to guide the definition of functions.
Brady E. Type-driven development with Idris.. Simon and Schuster, 2017
This definition of "Type-driven development" entails that each parser is defined at the outset to guarantee the production a particular data type (also called "data model", "data structure", or "schema"). With an abundance of different precisely defined data types in the code base, transformations can be defined with precise syntax as a cascade of data type conversions, e.g.:
list [ Any ] ⇩ list [ str ] ⇩ list [ conint ( ge = 0, le = 1000 ) ]*
* These data types were written using Python type hint notation, where conint(ge=0, le=1000) is
a pydantic data type representing a positive integer less
than or equal to 1000.
The data types remember
A main advantage of this approach is that once a variable is defined to follow a particular data type, e.g. "list of positive integers less than or equal to 1000", then this restriction is preserved in the data type itself; the variable never needs to be parsed or validated again!
Requires static typing
The "Parse, don't validate" approach requires that the programming language is statically typed and also that the language supports complex data types, so that e.g. a full metadata schema can be expressed as a type. It is no surprise that Alexis King in the above-mentioned blog post demonstrated the concepts in Haskell, a statically typed and purely functional programming language.
What about Python?
Python is one of the most popular programming languages in bioinformatics and data science in general. Python is also one of the most famous examples of a duck typed language, i.e. that if something "walks like a duck and quacks like a duck, then it must be a duck". Unfortunately, in traditional Python code, if a variable looks like a "list of positive integers less than 1000", there is no way to know this for sure without validating the full list, and even then, there are no guarantees that the data will stay that way forever.
Fortunately, with the integration of type hints and compile-time static type checkers such as mypy this is changing. Moveover, with the advent of run-time type checking with libraries like pydantic, the time is ripe to take advantage of type-driven design also in Python.
Technical note #2: Explanation of the concepts behind the slogan "Parse, don't validate" and the term "Type-driven development/design", and how this approach may be applied to Python
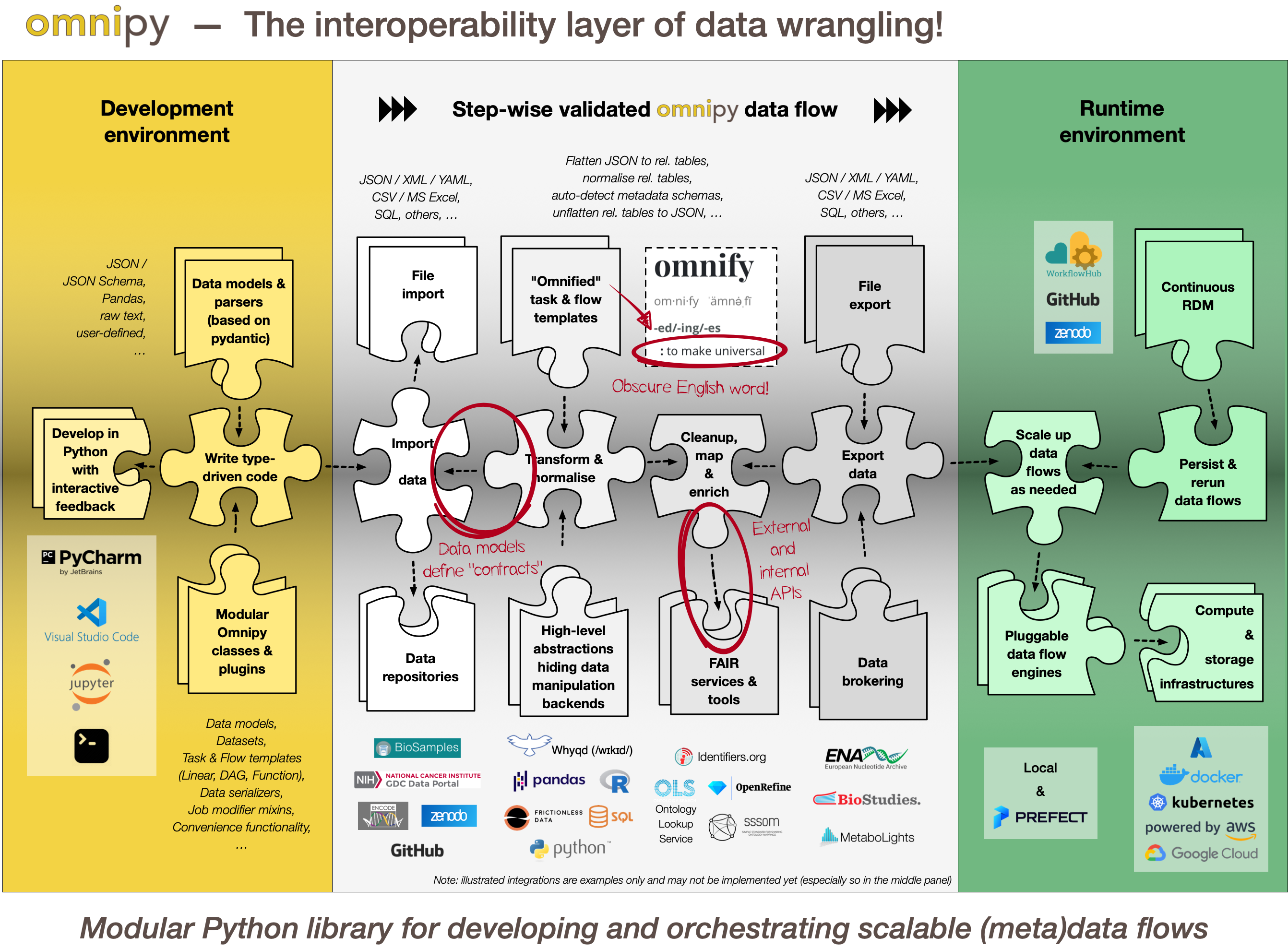
Figure 7.2: Conceptual overview of Omnipy, a Python package that in principle supports any type of data/metadata transformation workflows. Generic and modular processing steps are combined to create custom (meta)data transformation flows for particular use cases. The flows are run using a pluggable workflow engine, currently supporting local runs and the Prefect dataflow orchestration platform
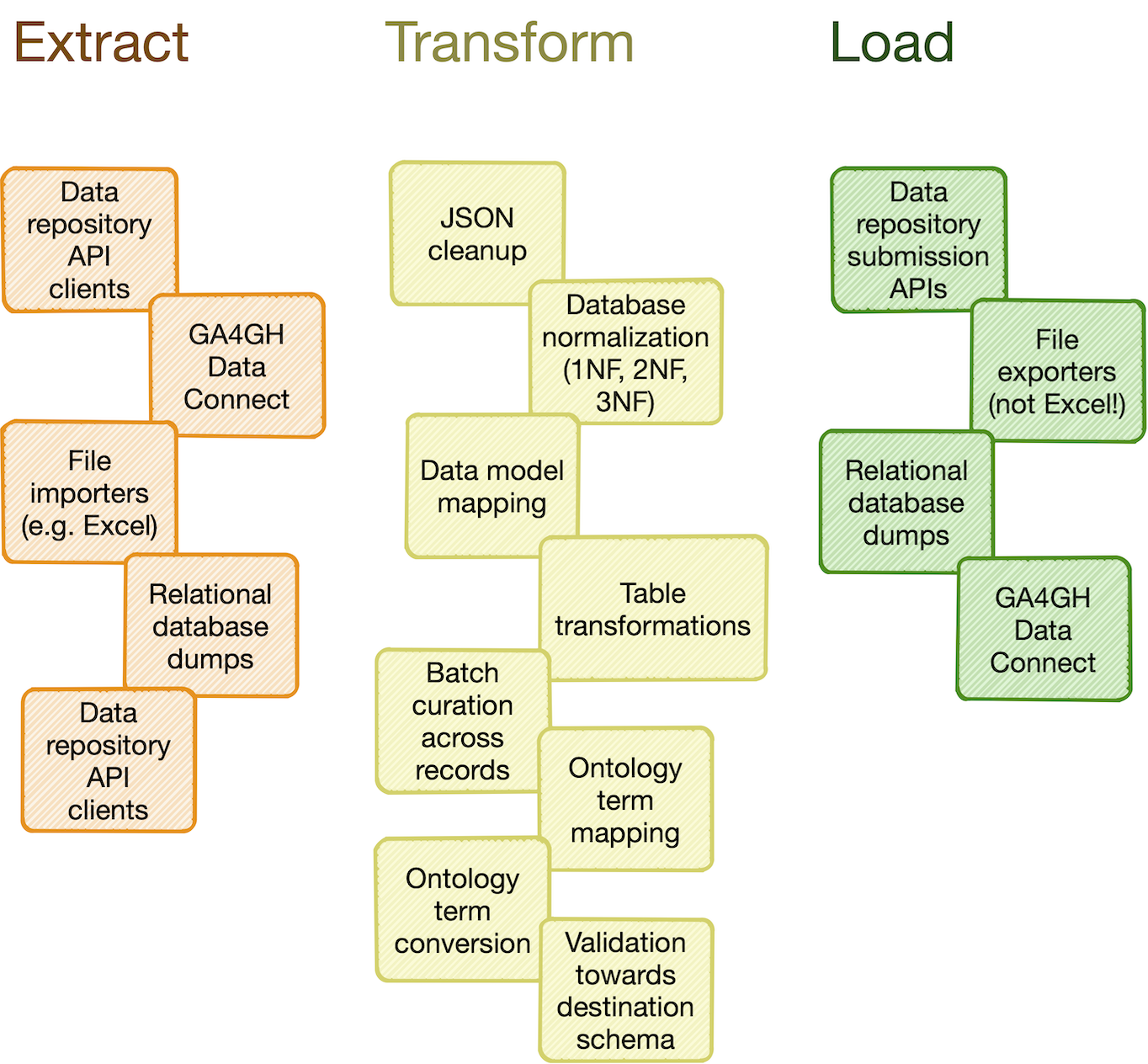
Figure 7.3: Examples of reusable modules that provide generic functionality for extraction, transformation and loading (ETL) of data or metadata. We aim to build a catalog of commonly useful processing steps, data modules and tool integrations (contributions are welcome)
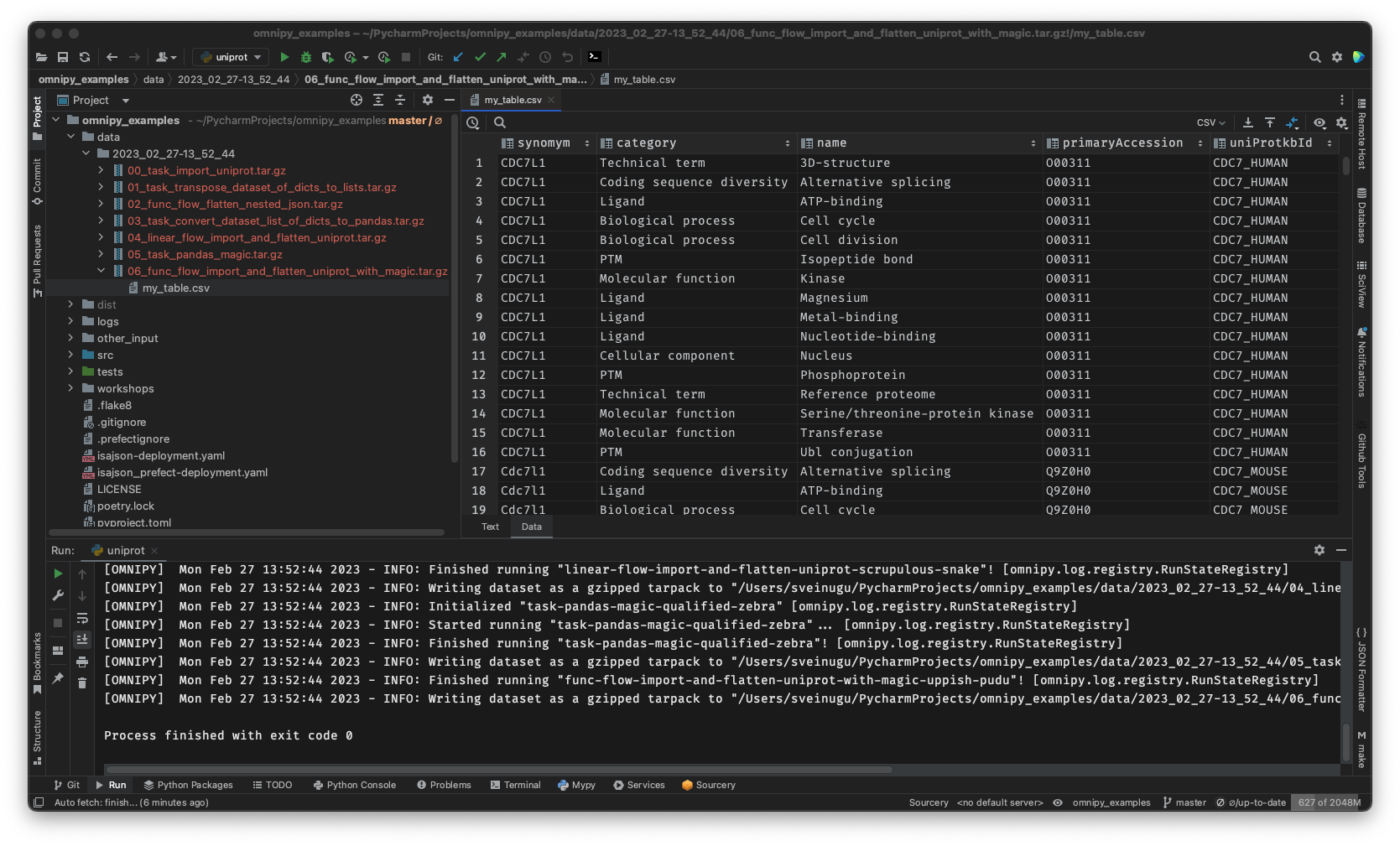
Figure 7.4: With Omnipy you can develop flows, inspect data, and deploy local or remote jobs, directly from an Integrated Development Environment (IDE). [Screenshot from Omnipy running in PyCharm]
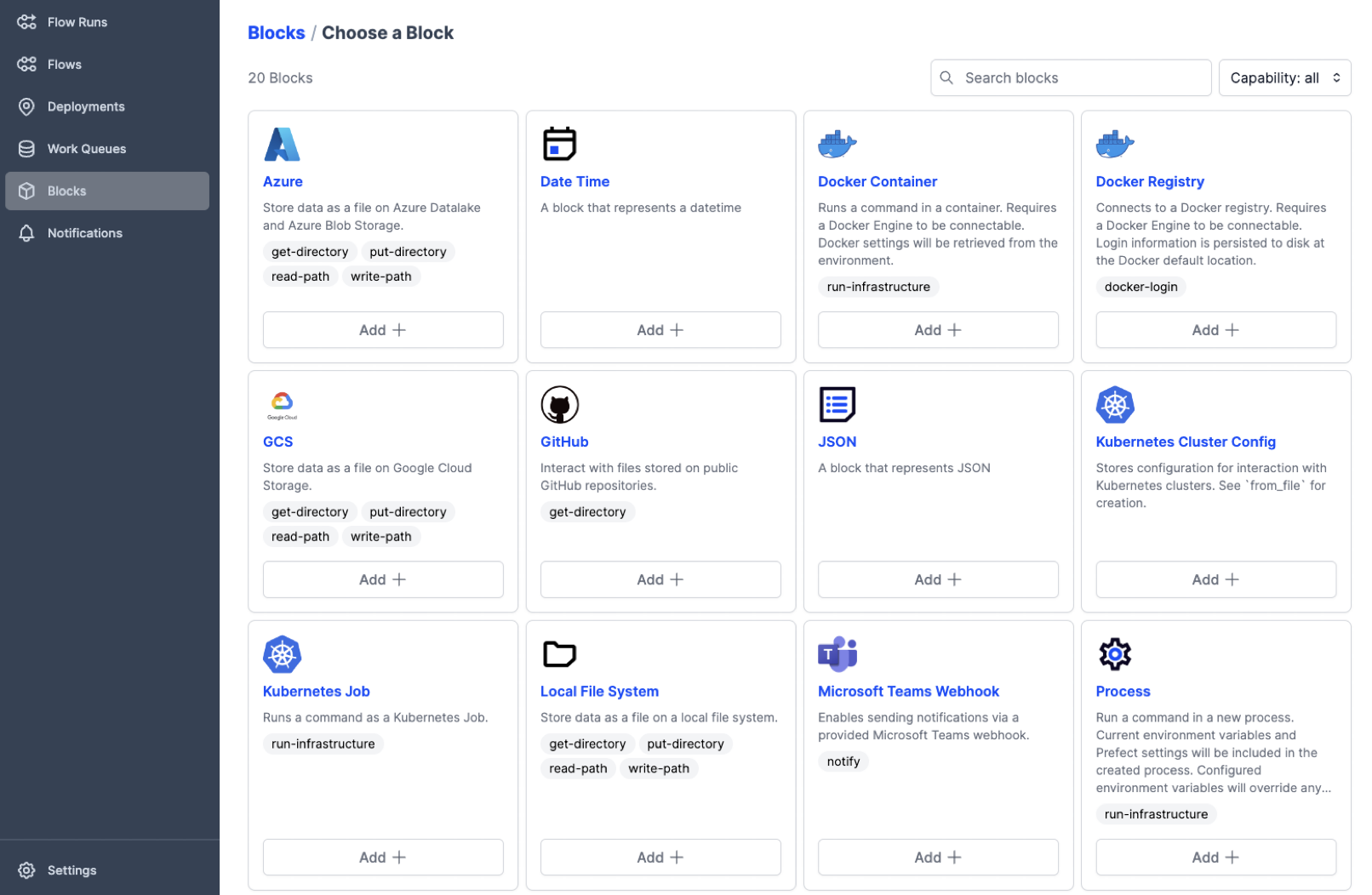
Figure 7.5: Overview of the compute and storage infrastructure integrations that comes built-in with Prefect. [Screenshot from the Prefect Web GUI, launched from an Omnipy installation]
Transformation
Principles and novel toolset for FAIRification and "data wrangling"
FAIR by design, FAIRification and Data brokering: There is a distinction between research data that has been made FAIR by design at the outset and research data that require a process of retroactive FAIRification (see Figure 7.1). In the FAIR-by-design case, metadata can be entered more or less directly according to the FAIR metadata schema, after which a validator can be applied to locate eventual errors. Retroactive FAIRification will, on the other hand, typically first require a process of transformation, cleaning, and mapping of the existing metadata from its previous shape into a new shape that follows a more FAIR-compliant schema. A similar process of metadata transformation and mapping happens in the process of data brokering, where metadata entered according to one metadata schema is automatically transformed to follow another schema and submitted to a data deposition service. In both cases, a validator will only be able to check the end result of a transformation process, it will not help much with the actual work of getting there.
In both cases, a validator will only be able to check the end result of a transformation process, it will not help much with the actual work of getting there
"Parse, don't validate": A complementary approach to applying a validator at the end is to uphold the schema restrictions through a set of data parsers in the transformation process itself. In contrast to validators, parsers will typically allow a level of variation and noise in the input data, but still make sure that the output data follow the relevant restrictions. This alternative approach to data wrangling can be summed up in the slogan "Parse, don't validate". See Technical note #2 (to the side) for a more in-depth look at this concept.
Validators as the authority: Parsing-based approaches are powerful, but still, in our view , complementary to traditional validators. As one often needs to set up several transformation processes, there is still the need of a single validator to be the authoritative judge in case of disagreements. Also, as mentioned above, parsers are not applicable to all scenarios.
FAIRtracks is a secondary metadata standard: Genomic track files are most often created as secondary by-products derived from the raw experiment data (see e.g. Finding Tracks). Hence, the choice of primary metadata schemas are typically dictated by circumstances relating to the raw data, e.g. to follow schemas required by research data management (RDM) or data deposition services (see Figure 1.3 in the section FAIR data and FAIRtracks above for an illustration of the secondary data life cycle in scope of the FAIRtracks project). For projects that are part of larger consortia undertakings, required metadata schemas are typically defined centrally (see Track collections). In both cases, the FAIRtracks standard is a secondary metadata exchange standard to that aims to facilitate interoperability and reuse of the data through a central indexing service and downstream software integrations (see Finding Tracks).
We are developing Omnipy, a systematic and scalable approach to research data transformation and "wrangling" in Python
The importance of a good solution for metadata transformation: Being a secondary metadata standard, it is imperative for community adoption of FAIRtracks that we provide good solutions for transforming metadata from its primary form into the FAIRtracks standard. To this end, we are developing Omnipy, a systematic and scalable approach to research data transformation and "wrangling" in Python.
![omnipy-logo-180-[fixed].png](/_nuxt/img/77c28e2.png)
Generic functionality: Omnipy is designed primarily to simplify development and deployment of (meta)data transformation processes in the context of FAIRification and data brokering efforts. However, the functionality is very generic and can also be used to support research data (and metadata) transformations in a range of fields and contexts beyond life science, including day-to-day research scenarios (see Figure 7.2).
Data wrangling in day-to-day research: Researchers in life science and other data-centric fields often need to extract, manipulate and integrate data and/or metadata from different sources, such as repositories, databases or flat files. Much research time is spent on trivial and not-so-trivial details of such "data wrangling":
- reformat data structures
- clean up errors
- remove duplicate data
- map and integrate dataset fields
- etc.
General software for data wrangling and analysis, such as Pandas, R or Frictionless, are useful, but researchers still regularly end up with hard-to-reuse scripts, often with manual steps.
Step-wise data model transformations: With the Omnipy Python package, researchers can import (meta)data in almost any shape or form: nested JSON; tabular (relational) data; binary streams; or other data structures. Through a step-by-step process, data is continuously parsed and reshaped according to a series of data model transformations.
Omnipy tasks (single steps) and flows (workflows) are defined as transformations from specific input data models to specific output data models.
"Parse, don't validate": Omnipy follows the type-driven design principles introduced in Technical note #2: "Parse, don't validate" (to the side). It makes use of cutting-edge Python type hints and the popular pydantic package to "pour" data into precisely defined data models that can range from very general (e.g. "any kind of JSON data", "any kind of tabular data", etc.) to very specific (e.g. "follow the FAIRtracks JSON Schema for track files with the extra restriction of only allowing BigBED files").
Data types as contracts: Omnipy tasks (single steps) or flows (workflows) are defined as transformations from specific input data models to specific output data models. pydantic-based parsing guarantees that the input and output data always follows the data models (i.e. data types). Thus, the data models defines "contracts" that simplifies reuse of tasks and flows in a mix-and-match fashion.
Catalog of common processing steps: Omnipy is built from the ground up to be modular. As also exemplified in Figure 7.3, we aim to provide a catalog of commonly useful functionality ranging from:
- data import from REST API endpoints, common flat file formats, database dumps, etc.
- flattening of complex, nested JSON structures
- standardization of relational tabular data (i.e. removing redundancy)
- mapping of tabular data between schemas
- lookup and mapping of ontology terms
- semi-automatic data cleaning (through e.g. Open Refine)
- support for common data manipulation software and libraries, such as Pandas, R, Frictionless, etc.
In particular, we will provide a FAIRtracks module that contains data models and processing steps to transform metadata to follow the FAIRtracks standard.
Refine and apply templates: A Omnipy module typically consists of a set of generic task and flow templates with related data models, (de)serializers, and utility functions. The user can then pick task and flow templates from this extensible, modular catalog, further refine them in the context of a custom, use case-specific flow, and apply them to the desired compute engine to carry out the transformations needed to wrangle data into the required shape.
Rerun only when needed: When piecing together a custom flow in Omnipy, the user has persistent access to the state of the data at every step of the process. Persistent intermediate data allows for caching of tasks based on the input data and parameters. Hence, if the input data and parameters of a task does not change between runs, the task is not rerun. This is particularly useful for importing from REST API endpoints, as a flow can be continuously rerun without taxing the remote server; data import will only be carried out in the initial iteration or when the REST API signals that the data has changed.
Scale up with external compute resources: In the case of large datasets, the researcher can set up a flow based on a representative sample of the full dataset, in a size that is suited for running locally on, say, a laptop. Once the flow has produced the correct output on the sample data, the operation can be seamlessly scaled up to the full dataset and sent off in software containers to run on external compute resources, using e.g. Kubernetes (see Figure 7.4). Such offloaded flows can be easily monitored using a web GUI.
Industry-standard ETL backbone: Offloading of flows to external compute resources is provided by the integration of Omnipy with a workflow engine based on the Prefect Python package. Prefect is an industry-leading platform for dataflow automation and orchestration that brings a series of powerful features to Omnipy:
- Predefined integrations with a range of compute infrastructure solutions (see Figure 7.5)
- Predefined integration with various services to support extraction, transformation, and loading (ETL) of data and metadata
- Code as workflow ("If Python can write it, Prefect can run it")
- Dynamic workflows: no predefined Direct Acyclic Graphs (DAGs) needed!
- Command line and web GUI-based visibility and control of jobs
- Trigger jobs from external events such as GitHub commits, file uploads, etc.
- Define continuously running workflows that still respond to external events
- Run tasks concurrently through support for asynchronous tasks
Pluggable workflow engines: It is also possible to integrate Omnipy with other workflow backends by implementing new workflow engine plugins. This is relatively easy to do, as the core architecture of Omnipy allows the user to easily switch the workflow engine at runtime. Omnipy supports both traditional DAG-based and the more avant-garde code-based definition of flows. Two workflow engines are currently supported: local and prefect.
Figure 7.1: The difference between making research (meta)data "FAIR by Design" from the outset and "FAIRifying Retrospectively". [From Goble, Carole: How are we Faring with FAIR? (and what FAIR is not). FAIRe Data Infrastructures, 15 October 2020. License: CC BY 4.0]
Tech note #2:
Parse, don't validate
Type-driven design
This alternative approach to data wrangling is summed up in a slogan coined by Alexis King in 2019 in an influential blog post: "Parse, don't validate". King here argues for the use of "Type-driven design", also called "Type-driven development":
Type-driven development is a style of programming in which we write types first and use those types to guide the definition of functions.
Brady E. Type-driven development with Idris.. Simon and Schuster, 2017
This definition of "Type-driven development" entails that each parser is defined at the outset to guarantee the production a particular data type (also called "data model", "data structure", or "schema"). With an abundance of different precisely defined data types in the code base, transformations can be defined with precise syntax as a cascade of data type conversions, e.g.:
list [ Any ] ⇩ list [ str ] ⇩ list [ conint ( ge = 0, le = 1000 ) ]*
* These data types were written using Python type hint notation, where conint(ge=0, le=1000) is
a pydantic data type representing a positive integer less
than or equal to 1000.
The data types remember
A main advantage of this approach is that once a variable is defined to follow a particular data type, e.g. "list of positive integers less than or equal to 1000", then this restriction is preserved in the data type itself; the variable never needs to be parsed or validated again!
Requires static typing
The "Parse, don't validate" approach requires that the programming language is statically typed and also that the language supports complex data types, so that e.g. a full metadata schema can be expressed as a type. It is no surprise that Alexis King in the above-mentioned blog post demonstrated the concepts in Haskell, a statically typed and purely functional programming language.
What about Python?
Python is one of the most popular programming languages in bioinformatics and data science in general. Python is also one of the most famous examples of a duck typed language, i.e. that if something "walks like a duck and quacks like a duck, then it must be a duck". Unfortunately, in traditional Python code, if a variable looks like a "list of positive integers less than 1000", there is no way to know this for sure without validating the full list, and even then, there are no guarantees that the data will stay that way forever.
Fortunately, with the integration of type hints and compile-time static type checkers such as mypy this is changing. Moveover, with the advent of run-time type checking with libraries like pydantic, the time is ripe to take advantage of type-driven design also in Python.
Technical note #2: Explanation of the concepts behind the slogan "Parse, don't validate" and the term "Type-driven development/design", and how this approach may be applied to Python
Figure 7.2: Conceptual overview of Omnipy, a Python package that in principle supports any type of data/metadata transformation workflows. Generic and modular processing steps are combined to create custom (meta)data transformation flows for particular use cases. The flows are run using a pluggable workflow engine, currently supporting local runs and the Prefect dataflow orchestration platform
Figure 7.3: Examples of reusable modules that provide generic functionality for extraction, transformation and loading (ETL) of data or metadata. We aim to build a catalog of commonly useful processing steps, data modules and tool integrations (contributions are welcome)
Figure 7.4: With Omnipy you can develop flows, inspect data, and deploy local or remote jobs, directly from an Integrated Development Environment (IDE). [Screenshot from Omnipy running in PyCharm]
Figure 7.5: Overview of the compute and storage infrastructure integrations that comes built-in with Prefect. [Screenshot from the Prefect Web GUI, launched from an Omnipy installation]